7.4. Lesson: Ruimtelijke statistieken¶
Notitie
Les ontwikkeld door Linfiniti en S Motala (Cape Peninsula University of Technology)
Ruimtelijke statistieken stellen u in staat te analyseren en te begrijpen wat er gaande is in een bepaalde vector gegevensset. QGIS bevat verschillende standaard gereedschappen voor statistische analyses die in dit opzicht hun nut hebben bewezen.
Het doel voor deze les: Weten hoe de ruimtelijke statistische gereedschappen in de Toolbox van Processing te gebruiken.
7.4.1.  Follow Along: Een test-gegevensset maken¶
Follow Along: Een test-gegevensset maken¶
We zullen een willekeurige verzameling van punten maken om een punt gegevensset te krijgen om mee te werken,
U heeft, om dat te doen, een polygoon gegevensset nodig die het bereik van het gebied waarin u de punten wilt maken definieert.
We zullen het gebied gebruiken dat wordt bedekt door straten.
Begin een nieuw project.
Voeg uw laag roads toe, als ook het rasterbestand srtm_41_19 (hoogtegegevens) te vinden in
exercise_data/raster/SRTM/.Notitie
U zou kunnen merken dat uw laag SRTM DEM een ander CRS heeft dan die van de laag roads. QGIS projecteert beide lagen in één enkel CRS. Voor de volgende oefeningen is dit verschil niet van belang, maar het staat u vrij een laag opnieuw te projecteren in een ander CRS zoals weergegeven in deze module.
Open de Toolbox van Processing.
Gebruik het gereedschap om een gebied te maken dat alle wegen omsluit door
Convex Hullte kiezen als de parameter Type geometrie:
Zoals u weet maakt Processing, als u geen uitvoer specificeert, tijdelijke lagen. Het is aan u om de lagen onmiddellijk op te slaan of op een later moment.
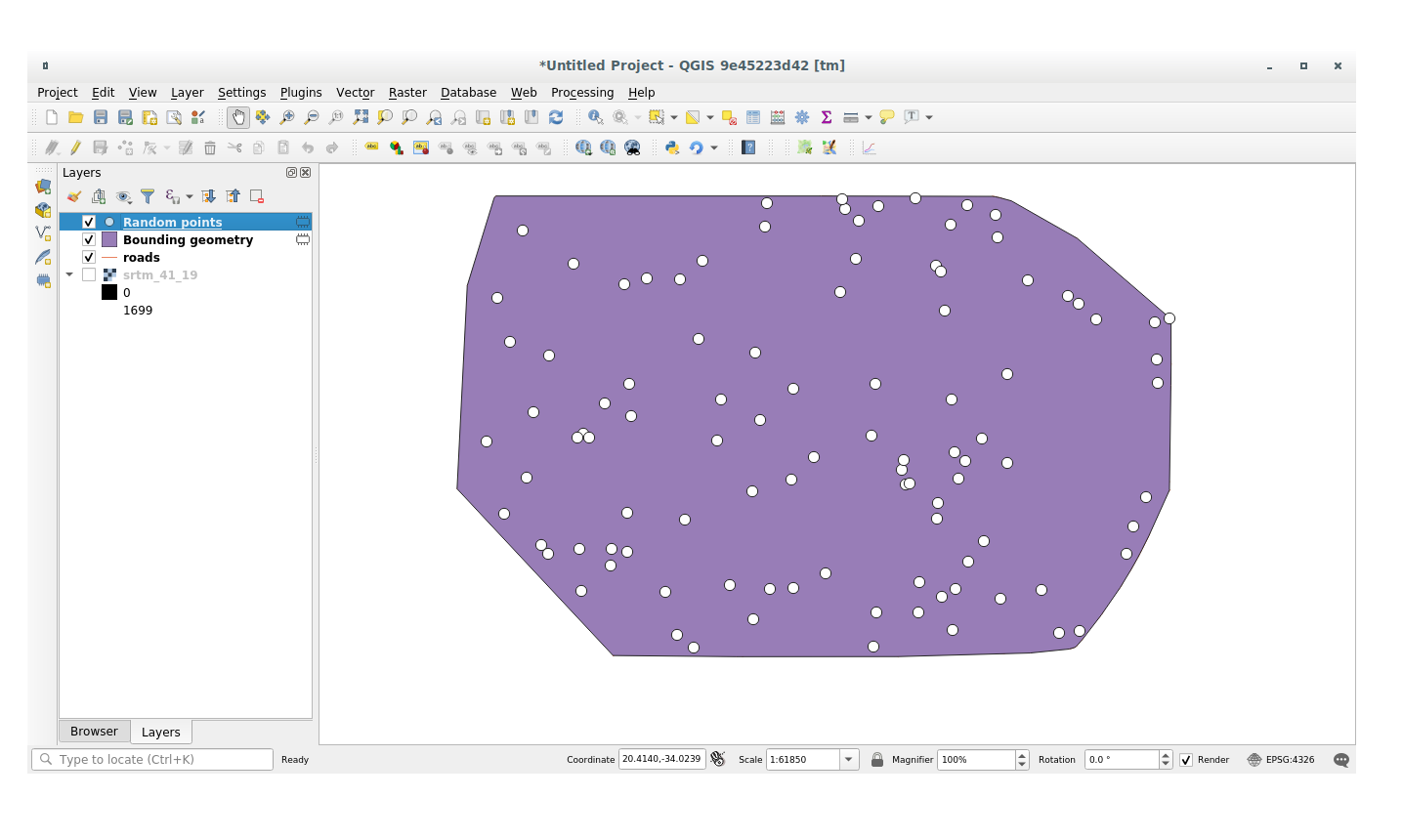
7.4.1.1. Willekeurige punten genereren¶
Maak in dit gebied willekeurige punten met het gereedschap :

Notitie
Het gele waarschuwingsteken vertelt u dat die parameter iets wil zeggen over de afstand. De laag Begrenzing geometrie staat in een Geografisch coördinatensysteem en het algoritme herinnert u daar slechts aan. Voor dit voorbeeld zullen we deze parameter niet gebruiken, dus kunt u het negeren.
Verplaats, indien nodig, de gemaakte willekeurige punten naar de boven in de legenda om hem beter te kunnen zien:
7.4.1.2. Een monster uit de gegevens¶
U dient het algoritme in de Toolbox van Processing te gebruiken om een gegevensset met monsters uit het raster te nemen. Dit gereedschap neemt monsters uit het raster op de locaties van de punten en kopieert de rasterwaarden in andere veld(en), afhankelijk van het feit uit hoeveel banden het raster is gemaakt.
Open het dialoogvenster voor het algoritme Monsters rasterwaarden
Selecteer random_points als de laag die de monsterpunten bevat en het SRTM-raster als de band waaruit de waarden moeten komen. De standaard naam voor het nieuwe veld is
rvalue_N, waarNhet nummer is van de rasterband. U kunt de naam van het voorvoegsel wijzigen als u dat wilt:
Klik op Uitvoeren
Nu kunt u de gegevens voor het monster uit het rasterbestand controleren in de attributentabel van de laag Monsterpunten, zij zullen in een nieuw veld, met de naam die u hebt gekozen, staan.
Een mogelijke laag voor het monster wordt hier weergegeven:

De monsterpunten worden door hun veld rvalue_1 geclassificeerd zodat rode punten op een hogere hoogte liggen.
U zult deze monsterlaag gaan gebruiken voor de rest van de statistische oefeningen.
7.4.2. Follow Along: Basisstatistieken¶
Nu nog de basisstatistieken voor deze laag ophalen.
Klik op het pictogram
 op de werkbalk Attributen in het hoofdvenster van QGIS. Een nieuw paneel zal openen.
op de werkbalk Attributen in het hoofdvenster van QGIS. Een nieuw paneel zal openen.Specificeer, in het dialoogvenster dat verschijnt, de laag Monsterpunten als de bron.
Selecteer het veld rvalue_1 in het combinatievak voor velden wat het veld is waarvoor u de statistieken wilt berekenen.
Het paneel Statistieken zal automatisch worden bijgewerkt met de berekende statistieken:

Notitie
U kunt de waarden kopiëren door te klikken op de knop
 Statistieken naar klembord kopiëren en de resultaten in een werkblad plakken.
Statistieken naar klembord kopiëren en de resultaten in een werkblad plakken.Sluit het paneel Statistieken indien gereed.
Veel verschillende statistieken zijn beschikbaar, hieronder enkele beschrijvingen:
- Telling
Het aantal monsters/waarden.
- Som
Alle waarden bij elkaar opgeteld.
- Gemiddelde
De gemiddelde waarde is eenvoudigweg de som van de waarden, gedeeld door het aantal waarden.
- Mediaan
Als u alle waarden schikt van de laagste tot de hoogste, is de middelste waarde (of het gemiddelde van de twee middelste waarden als N een even getal is) de mediaan van de waarden.
- St afw (pop)
De standaard afwijking. Geeft een indicatie over hoe dicht de waarden zijn geclusterd rondom het gemiddelde. Hoe kleiner de standaard afwijking, hoe meer waarden neigen naar het gemiddelde.
- Minimum
De laagste waarde.
- Maximum
De hoogste waarde.
- Bereik
Het verschil tussen de laagste en de hoogste waarden.
- Kw1
Eerste kwartiel van de gegevens.
- Kw3
Derde kwartiel van de gegevens.
- Ontbrekende (null) waarden
Totaal aantal waarden zonder gegevens
7.4.3. Follow Along: Statistieken berekenen van afstanden tussen punten met het gereedschap Afstandsmatrix¶
Maak een nieuwe puntenlaag als een
Tijdelijke laag.Ga naar modus Bewerken en digitaliseer drie punten ergens tussen de andere punten.
Gebruik, als alternatief, dezelfde methode voor het maken van willekeurige punten als hiervoor, maar specificeer slechts drie punten.
Sla uw nieuwe laag op als distance_points in de indeling die u wilt.
Statistieken maken over de afstand tussen punten in de twee lagen:
Open het gereedschap .
Selecteer de laag distance_points als de invoerlaag en de laag Monsterpunten als de doellaag.
Stel het als volgt in:

Als u wilt kunt u de uitvoerlaag opslaan als een bestand of alleen het algoritme uitvoeren en de tijdelijke uitvoerlaag op een later moment opslaan.
Klik op Uitvoeren om de laag voor de afstandsmatrix te maken.
Open de attributentabel van de gemaakte laag: waarden verwijzen naar de afstanden tussen de objecten van Afstandsmatrix en hun twee dichtstbijzijnde punten op de laag Monsterpunten:

Met deze parameters berekent het gereedschap Afstandsmatrix statistieken over de afstanden voor elk punt van de invoerlaag ten opzichte van de dichtstbijzijnde punten van de doellaag. De velden van de uitvoerlaag bevatten gemiddelde, standaard afwijking, minimum en maximum voor de afstanden tot de dichtst bij gelegen buren van de punten op de invoerlaag.
7.4.4. Follow Along: ‘Dichtstbijzijnde buur’-analyse (in laag)¶
Een ‘Dichtstbijzijnde buur’-analyse uitvoeren op een puntenlaag:
Klik op het menu-item .
Selecteer, in het dialoogvenster dat verschijnt, de laag Random samples en klik op Uitvoeren.
De resultaten zullen verschijnen in het paneel van Processing Resultaten bekijken.

Klik op de blauwe link om de ``HTML`- pagina met de resultaten te bekijken:

7.4.5. Follow Along: Gemiddelde coördinaten¶
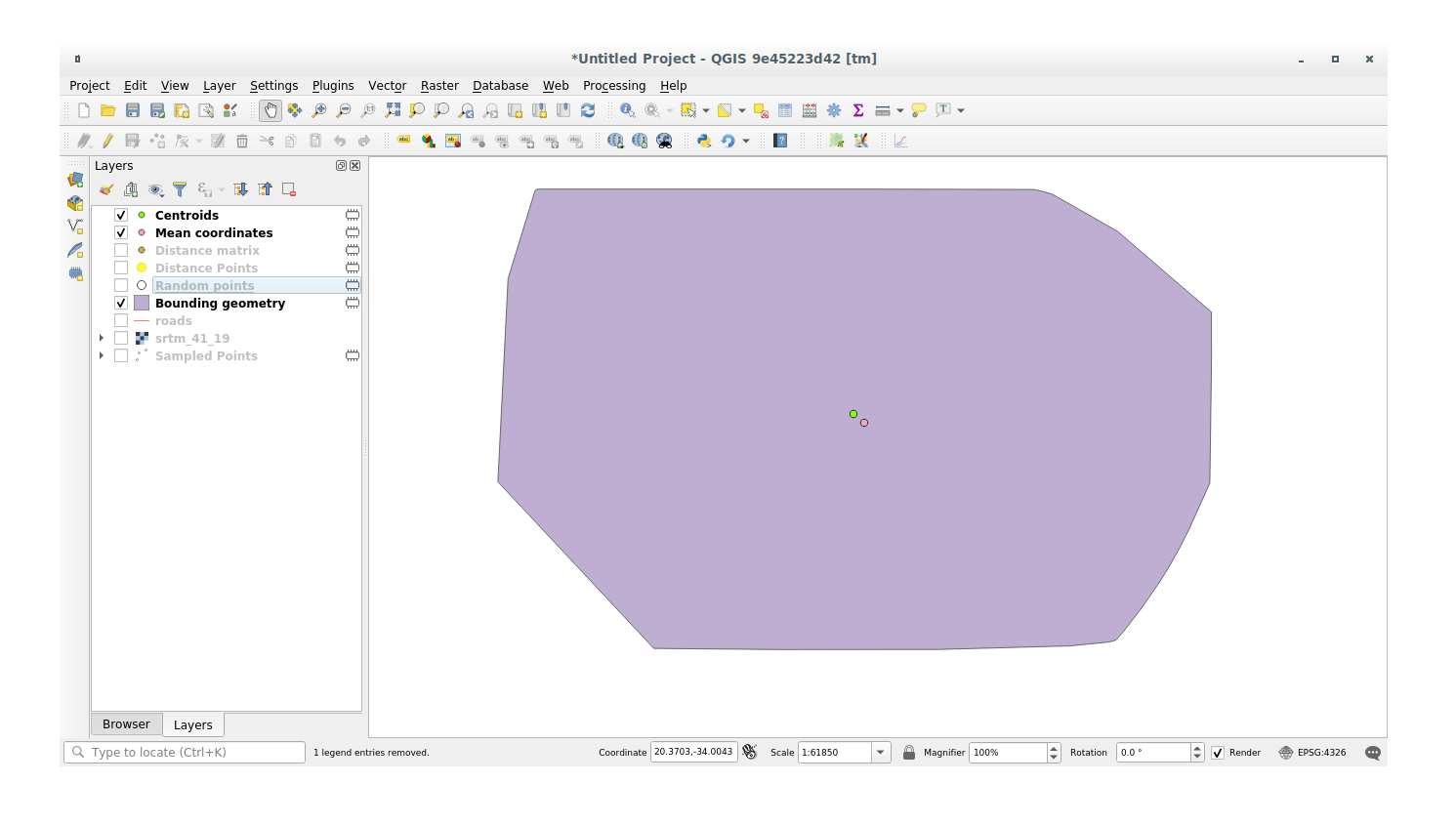
De gemiddelde coördinaten van een gegevensset verkrijgen:
Klik op het menu-item .
Specificeer, in het dialoogvenster dat verschijnt, Willekeurige punten als de invoerlaag, maar laat de optionele keuzen ongewijzigd.
Klik op Uitvoeren.
Laten we dit eens vergelijken met de centrale coördinaat van de polygoon die werd gebruikt om het willekeurige monster te maken.
Klik op het menu-item .
Selecteer, in het dialoogvenster dat verschijnt, Begrenzing geometrie als de invoerlaag.
Zoals u in het voorbeeld hieronder kunt zien vallen de gemiddelde coördinaten (roze punt) en het middelpunt van het gebruikte gebied (in groen) niet noodzakelijkerwijze samen.
Het zwaartepunt is het barycenter van de laag (het barycenter van een vierkant is het midden van het vierkant) terwijl de gemiddelde coördinaten het gemiddelde weergeven van alle coördinaten van de knopen.
7.4.6. Follow Along: Histogrammen van afbeeldingen¶
Het histogram van een gegevensset geeft de verdeling van de waarden ervan weer. De eenvoudigste manier om dit in QGIS te demonstreren is via het histogram van een afbeelding, beschikbaar in het dialoogvenster Laageigenschappen van elke afbeeldingslaag (raster gegevensset).
Klik, in uw paneel Lagen, met rechts op de laag srtm_41_19.
Selecteer .
Kies de tab Histogram. U moet misschien op de knop Histogram herberekenen klikken om de grafiek te maken. U zult een grafiek zien die de frequentie van de waarden in de afbeelding beschrijft.
U kunt dat als een afbeelding exporteren:

Selecteer de tab Informatie, u kunt dan meer gedetailleerde informatie van de laag bekijken.
De gemiddelde waarde is 332.8, en de hoogste waarde is 1699! Maar deze waarden zijn niet zichtbaar in het histogram. Waarom niet? Dat komt omdat er maar zo weinig van zijn, vergeleken met de overvloed aan pixels met waarden onder het gemiddelde. Dat is ook waarom het histogram zich zo ver naar rechts uitstrekt, zelfs hoewel er geen zichtbare rode lijn is die de frequentie markeert van waarden hoger dan ongeveer 250.
Notitie
Als de gemiddelde en maximum waarden niet hetzelfde zijn als die in het voorbeeld kan dat zijn vanwege de berekening van de waarde min/max. Open de tab Symbologie en vergroot het menu Instellingen Min- / Max-waarden. Kies  Min / max en klik op Apply.
Min / max en klik op Apply.
Onthoud daarom dat een histogram u de verdeling van de waarden laat zien en dat niet alle waarden noodzakelijkerwijze ook zichtbaar zijn in de grafiek.
7.4.7. Follow Along: Ruimtelijke interpolatie¶
Laten we zeggen dat u een collectie monsterpunten heeft van waaruit u gegevens wilt extrapoleren. U heeft misschien toegang tot de gegevensset Monsterpunten die we eerder gemaakt hebben en wil een idee krijgen over hoe het terrein eruit ziet.
Start, om te beginnen, het gereedschap in de Toolbox van Processing.
Selecteer, als de parameter Puntenlaag, Monsterpunten
Stel
5.0in als de Gewogen machtStel, onder de Gevorderde parameters, rvalue_1 in voor de parameter Z-waarde uit veld
Klik tenslotte op Uitvoeren en wacht tot het algoritme is voltooid.
Sluit het dialoogvenster
Hier is een vergelijking van de originele gegevensset (links) met die welke we hebben gemaakt uit onze monsterpunten (rechts). Die van u kan er anders uitzien vanwege de willekeurige herkomst van de locatie van de monsterpunten.

Zoals u kunt zien zijn 100 monsterpunten niet echt genoeg om een gedetailleerde impressie van het terrein te maken. Het geeft een zeer algemeen idee, maar het kan ook misleidend zijn.
7.4.8.  Try Yourself Verschillende methoden voor interpolatie¶
Try Yourself Verschillende methoden voor interpolatie¶
Gebruik de hierboven weergegeven processen om een nieuwe set van
10.000willekeurige punten te maken.Notitie
Als de hoeveelheid punten echt heel groot is kan de verwerkingstijd behoorlijk oplopen.
Gebruik die punten om een monster te nemen uit de originele DEM.
Gebruik het gereedschap Raster (IDW met zoeken naar Nearest neighbor) op deze nieuwe gegevensset, zoals hierboven.
Stel Macht en Afvlakken respectievelijk in op
5.0en op2.0.
De resultaten (afhankelijk van de positie van uw willekeurige punten) zal er min of meer zo uitzien:

Dit is een veel betere weergave van het terrein, vanwege de veel hogere dichtheid van monsterpunten. Onthoud: meer monsters geven betere resultaten.
7.4.9. In Conclusion¶
QGIS heeft vele mogelijkheden voor het analyseren van de ruimtelijke statistische eigenschappen van gegevenssets.
7.4.10. What’s Next?¶
Nu we vectoranalyse hebben behandeld, waarom niet eens kijken wat er met rasters gedaan kan worden? Dat is wat we zullen gaan doen in de volgende module!