23.1.12. 벡터 분석¶
23.1.12.1. 필드에 대한 기본 통계¶
벡터 레이어의 속성 테이블에 있는 필드에 대한 기본 통계를 생성합니다.
숫자, 날짜, 시간 및 문자열 필드를 지원합니다.
필드 유형에 따라 반환되는 통계가 달라질 것입니다.
통계는 HTML 파일로 생성되며 메뉴로 볼 수 있습니다.
기본 메뉴:
23.1.12.1.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input vector |
|
[vector: any] |
통계를 계산할 벡터 레이어 |
Field to calculate statistics on |
|
[tablefield: any] |
통계를 계산할 지원하는 테이블 필드 |
Statistics |
|
[html] |
계산된 통계를 가진 HTML 파일 |
23.1.12.1.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Statistics |
|
[html] |
계산된 통계를 가진 HTML 파일 |
Count |
|
[number] |
|
Number of unique values |
|
[number] |
|
Number of empty (null) values |
|
[number] |
|
Number of non-empty values |
|
[number] |
|
Minimum value |
|
[same as input] |
|
Maximum value |
|
[same as input] |
|
Minimum length |
|
[number] |
|
Maximum length |
|
[number] |
|
Mean length |
|
[number] |
|
Coefficient of Variation |
|
[number] |
|
Sum |
|
[number] |
|
Mean value |
|
[number] |
|
Standard deviation |
|
[number] |
|
Range |
|
[number] |
|
Median |
|
[number] |
|
Minority (rarest occurring value) |
|
[same as input] |
|
Majority (most frequently occurring value) |
|
[same as input] |
|
First quartile |
|
[number] |
|
Third quartile |
|
[number] |
|
Interquartile Range (IQR) |
|
[number] |
23.1.12.1.3. 파이썬 코드¶
Algorithm ID: qgis:basicstatisticsforfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.2. 라인을 따라 오르막¶
라인 도형을 따라 총 오르막(climb)과 내리막(descent)을 계산합니다. 입력 레이어가 Z 값을 가지고 있어야만 합니다. Z 값을 사용할 수 없는 경우, 늘어뜨리기 (래스터로부터 Z 값 설정하기) 알고리즘을 사용해서 DEM 레이어로부터 Z 값을 추가할 수도 있습니다.
산출 레이어는 입력 레이어에 각 라인 도형의 총 오르막(climb), 총 내리막(descent), 최저 표고(minelev) 및 최고 표고(maxelev)를 담고 있는 필드를 추가한 복사본입니다. 입력 레이어가 이렇게 추가되는 필드와 동일한 명칭을 가진 필드를 가지고 있는 경우, 기존 필드를 재명명할 것입니다. (《name_2》, 《name_3》 등으로 첫 번째로 일치하지 않는 명칭을 찾아 필드명을 수정할 것입니다.)
23.1.12.2.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Line layer |
|
[vector: line] |
오르막을 계산할 라인 레이어입니다. Z 값을 가지고 있어야만 합니다. |
Climb layer |
|
[vector: line] |
산출 (라인) 레이어 |
23.1.12.2.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Climb layer |
|
[vector: line] |
오르막 계산에서 나온 결과를 가진 새 속성을 담고 있는 라인 레이어 |
Total climb |
|
[number] |
입력 레이어에 있는 모든 라인 도형에 대한 오르막 합계 |
Total descent |
|
[number] |
입력 레이어에 있는 모든 라인 도형에 대한 내리막 합계 |
Minimum elevation |
|
[number] |
레이어에 있는 도형 가운데 최저 표고 |
Maximum elevation |
|
[number] |
레이어에 있는 도형 가운데 최고 표고 |
23.1.12.2.3. 파이썬 코드¶
Algorithm ID: qgis:climbalongline
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.3. 폴리곤에서 포인트 개수 세기¶
포인트 레이어와 폴리곤 레이어를 받아 폴리곤 레이어의 각 폴리곤 내부에 들어오는 포인트 레이어의 포인트 개수를 셉니다.
입력 폴리곤 레이어와 정확히 동일한 내용을 가지면서, 각 폴리곤에 대응하는 포인트 개수를 가진 추가 필드를 담고 있는 새 폴리곤 레이어를 생성합니다.
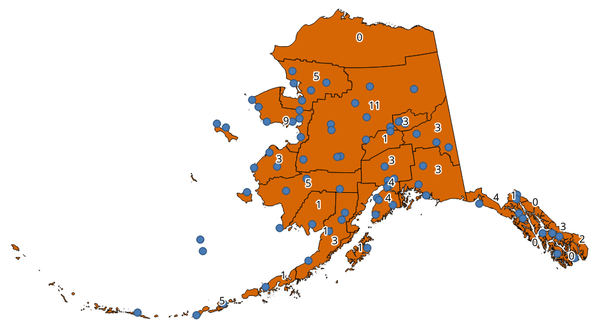
그림 23.17 포인트 개수를 표시하는 폴리곤 라벨¶
각 포인트에 가중치를 할당하기 위해 부가적인 가중치 필드를 사용할 수 있습니다. 또는, 유일 범주 필드를 지정할 수 있습니다. 이 두 옵션을 모두 사용하는 경우, 가중치 필드를 우선하고 유일 범주 필드는 무시할 것입니다.
기본 메뉴:
23.1.12.3.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Polygons |
|
[vector: polygon] |
포인트의 개수를 셀 피처를 가진 폴리곤 레이어 |
Points |
|
[vector: point] |
개수를 셀 포인트 레이어 |
Weight field 부가적 |
|
[tablefield: any] |
포인트 레이어의 필드. 생성된 개수는 폴리곤이 담고 있는 포인트의 가중치 필드의 합계가 될 것입니다. 가중치 필드가 숫자가 아닌 경우, 개수는 |
Class field 부가적 |
|
[tablefield: any] |
선택한 속성을 기반으로 포인트를 범주화해서 폴리곤 내부에 동일한 속성값을 가진 포인트가 여러 개 있는 경우, 하나로 셉니다. 따라서 폴리곤에 들어오는 포인트의 최종 개수는 폴리곤에서 발견된 서로 다른 범주의 개수입니다. |
Count field name |
|
[string] 기본값: 〈NUMPOINTS〉 |
포인트 개수를 저장할 필드의 명칭 |
Count |
|
[vector: polygon] |
산출 레이어를 지정합니다. |
23.1.12.3.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Count |
|
[vector: polygon] |
포인트 개수를 가진 새 열을 담고 있는 속성 테이블을 가진 산출 레이어 |
23.1.12.4. DBSCAN 군집 형성¶
이상값(noise) (DBSCAN) 알고리즘을 가진 응용 프로그램의 밀도 기반 공간 군집 형성의 2차원 구현을 기반으로 포인트 피처를 군집시킵니다.
이 알고리즘은 최소 군집 크기 파라미터 및 군집 포인트 사이에 허용된 최장 거리 파라미터, 2개를 필요로 합니다.
더 보기
23.1.12.4.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layer |
|
[vector: point] |
분석할 레이어 |
Minimum cluster size |
|
[number] 기본값: 5 |
군집을 형성할 피처의 최소 개수 |
Maximum distance between clustered points |
|
[number] 기본값: 1.0 |
이 거리(eps)를 초과하면 동일 군집에 속할 수 없습니다. |
Cluster field name |
|
[string] 기본값: 〈CLUSTER_ID〉 |
연관 군집 번호를 저장할 필드의 명칭 |
Treat border points as noise (DBSCAN*) 부가적 |
|
[boolean] 기본값: False |
|
Clusters |
|
[vector: point] |
군집 형성의 결과를 담은 벡터 레이어 |
23.1.12.4.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Clusters |
|
[vector: point] |
원본 피처와 함께 원본 피처가 속한 군집을 설정하는 필드를 가진 벡터 레이어 |
Number of clusters |
|
[number] |
발견된 군집의 개수 |
23.1.12.4.3. 파이썬 코드¶
Algorithm ID: qgis:dbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.5. 거리 매트릭스¶
어떤 포인트 피처와 동일 레이어 또는 다른 레이어에 있는 최근접 피처 사이의 거리를 계산합니다.
기본 메뉴:
더 보기
23.1.12.5.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input point layer |
|
[vector: point] |
(포인트 로부터) 거리 매트릭스를 계산할 포인트 레이어 |
Input unique ID field |
|
[tablefield: any] |
입력 레이어의 피처를 유일하게 식별하기 위해 사용하는 필드입니다. 산출 속성 테이블에 사용됩니다. |
Target point layer |
|
[vector: point] |
(포인트 로) 검색할 최근접 포인트(들)를 담고 있는 포인트 레이어 |
Target unique ID field |
|
[tablefield: any] |
대상 레이어의 피처를 유일하게 식별하기 위해 사용하는 필드입니다. 산출 속성 테이블에 사용됩니다. |
Output matrix type |
|
[enumeration] 기본값: 0 |
서로 다른 계산 유형을 사용할 수 있습니다:
|
Use only the nearest (k) target points |
|
[number] 기본값: 0 |
대상 레이어에 있는 모든 포인트(0)까지의 거리를 계산하거나, 또는 최근접 피처의 개수(k)로 제한할 수 있습니다. |
Distance matrix |
|
[vector: point] |
23.1.12.5.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Distance matrix |
|
[vector: point] |
각 입력 피처별로 계산한 거리를 담고 있는 포인트 (또는 《Linear (N * k x 3)》 의 경우 멀티포인트) 벡터 레이어입니다. 이 레이어의 피처와 속성 테이블은 선택한 산출 매트릭스 유형에 따라 달라집니다. |
23.1.12.5.3. 파이썬 코드¶
Algorithm ID: qgis:distancematrix
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.6. 최근접 허브까지의 거리 (라인에서 허브로)¶
입력 벡터 레이어의 각 피처를 대상 레이어에 있는 최근접 피처에 결합(join)시키는 라인을 생성합니다. 각 피처의 중심(center) 을 기반으로 거리를 계산합니다.
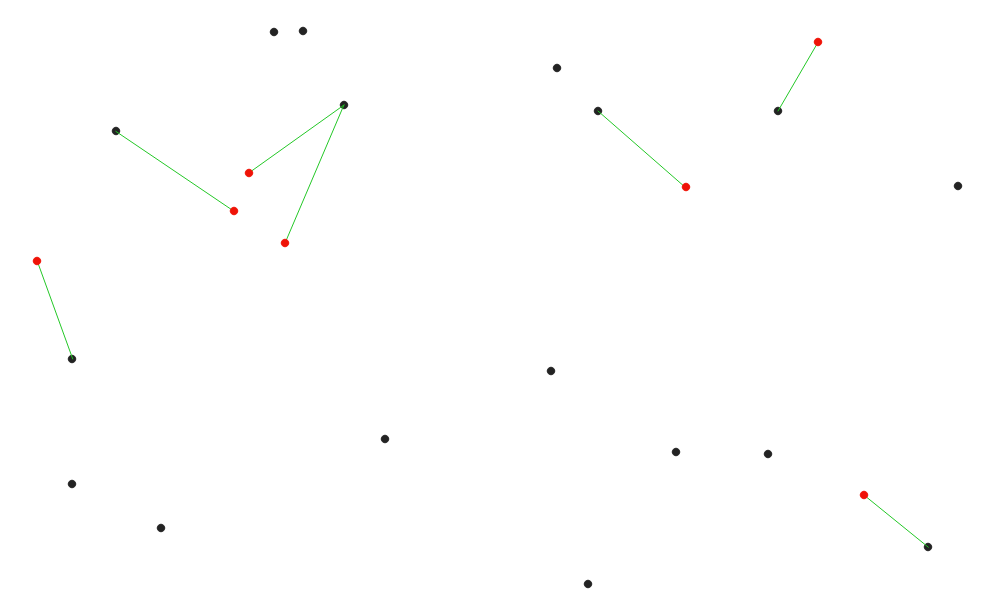
그림 23.18 빨간색 입력 피처의 최근접 허브를 표시¶
23.1.12.6.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Source points layer |
|
[vector: any] |
최근접 피처를 검색할 벡터 레이어 |
Destination hubs layer |
|
[vector: any] |
검색할 피처를 담고 있는 벡터 레이어 |
Hub layer name attribute |
|
[tablefield: any] |
대상 레이어의 피처를 유일하게 식별하기 위해 사용하는 필드입니다. 산출 속성 테이블에 사용됩니다. |
Measurement unit |
|
[enumeration] 기본값: 0 |
최근접 피처까지의 거리를 보고하기 위한 단위
|
Hub distance |
|
[vector: line] |
거리 매트릭스 산출물을 저장할 라인 벡터 레이어 |
23.1.12.6.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Hub distance |
|
[vector: line] |
입력 피처, 최근접 피처의 식별자, 계산된 거리의 속성을 가진 라인 벡터 레이어 |
23.1.12.6.3. 파이썬 코드¶
Algorithm ID: qgis:distancetonearesthublinetohub
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.7. 최근접 허브까지의 거리 (포인트)¶
입력 피처의 중심(center) 을 표현하는 포인트 레이어를 최근접 피처의 (중심 포인트를 기반으로 하는) 식별자 및 포인트들 사이의 거리를 담고 있는 필드 2개를 추가해서 생성합니다.
23.1.12.7.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Source points layer |
|
[vector: any] |
최근접 피처를 검색할 벡터 레이어 |
Destination hubs layer |
|
[vector: any] |
검색할 피처를 담고 있는 벡터 레이어 |
Hub layer name attribute |
|
[tablefield: any] |
대상 레이어의 피처를 유일하게 식별하기 위해 사용하는 필드입니다. 산출 속성 테이블에 사용됩니다. |
Measurement unit |
|
[enumeration] 기본값: 0 |
최근접 피처까지의 거리를 보고하기 위한 단위
|
Hub distance |
|
[vector: point] |
거리 매트릭스 산출물을 저장할 포인트 벡터 레이어 |
23.1.12.7.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Hub distance |
|
[vector: point] |
입력 피처, 최근접 피처의 식별자, 계산된 거리의 속성을 가진 포인트 벡터 레이어 |
23.1.12.7.3. 파이썬 코드¶
Algorithm ID: qgis:distancetonearesthubpoints
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.8. 라인으로 결합 (허브 라인)¶
스포크 레이어의 포인트에서 허브 레이어의 일치하는 포인트로 라인을 연결해서 허브&스포크(hub and spoke) 다이어그램을 생성합니다.
허브 포인트의 허브 ID 필드와 스포크 포인트의 스포크 ID 필드 사이의 일치 여부를 바탕으로 어떤 허브가 각 포인트와 연결될지 결정합니다.
입력 레이어가 포인트 레이어가 아닌 경우, 도형의 표면 상에 있는 포인트를 연결 위치로 삼을 것입니다.
측지선(測地線; geodesic line)을 부가적으로 생성할 수 있습니다. 측지선이란 타원체의 표면 상에서 두 점을 잇는 최단 경로를 말합니다. 측지 모드를 사용하는 경우, 반대 자오선(antimeridian; ±180˚ 경도)에서 생성된 라인을 분할할 수 있습니다. 이렇게 하면 라인 렌더링을 향상시킬 수 있습니다. 또, 꼭짓점 사이의 거리를 지정할 수 있습니다. 거리가 짧을수록 더 밀집한, 더 정확한 라인을 산출합니다.
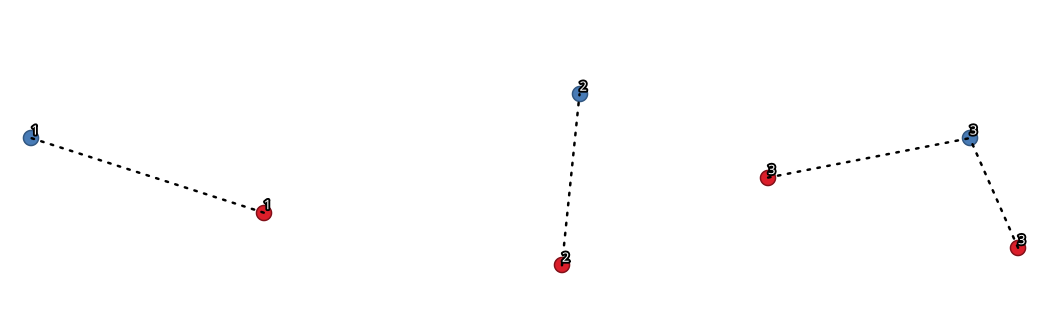
그림 23.19 공통 필드/속성을 바탕으로 포인트 결합¶
23.1.12.8.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Hub layer |
|
[vector: any] |
입력 레이어 |
Hub ID field |
|
[tablefield: any] |
결합을 위한 ID를 가진 허브 레이어의 필드 |
Hub layer fields to copy (leave empty to copy all fields) 부가적 |
|
[tablefield: any] [list] |
복사할 허브 레이어의 필드(들). 아무 필드도 선택하지 않을 경우 모든 필드를 복사합니다. |
Spoke layer |
|
[vector: any] |
부가적인 스포크 포인트 레이어 |
Spoke ID field |
|
[tablefield: any] |
결합을 위한 ID를 가진 스포크 레이어의 필드 |
Spoke layer fields to copy (leave empty to copy all fields) 부가적 |
|
[tablefield: any] [list] |
복사할 스포크 레이어의 필드(들). 아무 필드도 선택하지 않을 경우 모든 필드를 복사합니다. |
Create geodesic lines |
|
[boolean] 기본값: False |
측지선(타원체 표면 상에서 두 점을 잇는 최단 경로)을 생성합니다. |
Distance between vertices (geodesic lines only) |
|
[number] 기본값: 1000.0 (킬로미터) |
연속하는 꼭짓점 사이의 (킬로미터 단위) 거리. 거리가 짧을수록 더 밀집한, 더 정확한 라인을 산출합니다. |
Split lines at antimeridian (±180 degrees longitude) |
|
[boolean] 기본값: False |
±180˚ 경도에서 라인을 (라인 렌더링을 향상시키기 위해) 분할합니다. |
Hub lines |
|
[vector: line] |
산출되는 라인 레이어 |
23.1.12.8.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Hub lines |
|
[vector: line] |
산출되는 라인 레이어 |
23.1.12.8.3. 파이썬 코드¶
Algorithm ID: qgis:hublines
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.9. k-평균 군집 형성¶
각 입력 피처에 대해 k-평균 군집 개수를 바탕으로 2차원 거리를 계산합니다.
k-평균 군집 형성은 피처들을 각 피처가 최근접 평균을 가진 군집에 속하는 k개의 군집으로 나누는 것을 목적으로 합니다. 평균 포인트는 군집된 피처들의 무게중심(barycenter)으로 표현됩니다.
입력 도형이 라인 또는 폴리곤인 경우, 피처의 중심(centroid)을 기반으로 군집을 형성합니다.
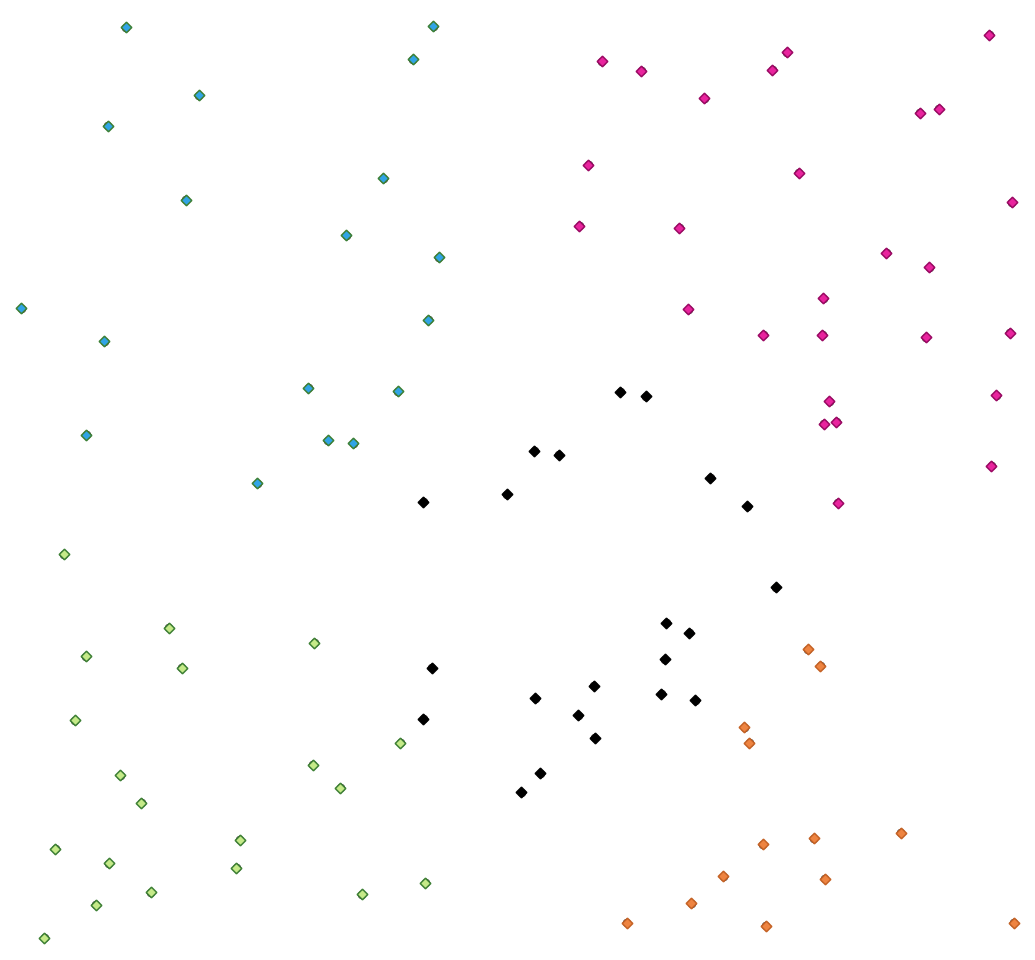
그림 23.20 범주가 5개인 포인트 군집들¶
더 보기
23.1.12.9.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layer |
|
[vector: any] |
분석할 레이어 |
Number of clusters |
|
[number] 기본값: 5 |
피처를 통해 생성할 군집의 개수 |
Cluster field name |
|
[string] 기본값: 〈CLUSTER_ID〉 |
군집 개수 필드의 명칭 |
Clusters |
|
[vector: any] |
생성된 군집을 담은 벡터 레이어 |
23.1.12.9.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Clusters |
|
[vector: any] |
원본 피처와 함께 원본 피처가 속한 군집을 지정하는 필드를 가진 벡터 레이어 |
23.1.12.9.3. 파이썬 코드¶
Algorithm ID: qgis:kmeansclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.10. 유일 값 목록¶
속성 테이블 필드에서 유일 값(unique value)을 목록화하고 그 개수를 셉니다.
기본 메뉴:
23.1.12.10.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layer |
|
[vector: any] |
분석할 레이어 |
Target field(s) |
|
[tablefield: any] |
분석할 필드 |
Unique values |
|
[table] |
유일 값을 가진 요약 테이블 레이어 |
HTML report |
|
[html] |
유일 값의 HTML 보고서. 메뉴로 볼 수 있습니다. |
23.1.12.10.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Unique values |
|
[table] |
유일 값을 가진 요약 테이블 레이어 |
HTML report |
|
[html] |
유일 값의 HTML 보고서. 메뉴로 볼 수 있습니다. |
Total unique values |
|
[number] |
입력 필드에 있는 유일 값들의 개수 |
UNIQUE_VALUES |
|
[string] |
입력 필드에서 발견된 유일 값을 쉼표로 구분한 목록의 문자열 |
23.1.12.10.3. 파이썬 코드¶
Algorithm ID: qgis:listuniquevalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.11. 평균 좌표(들)¶
입력 좌표에 있는 도형 무리(mass)의 중심(center)을 가진 포인트 레이어를 계산합니다.
무리의 중심을 계산할 때 각 피처에 적용할 가중치를 담고 있는 속성을 지정할 수 있습니다.
파라미터에서 속성을 선택한 경우, 해당 필드에 있는 값에 따라 피처를 그룹화할 것입니다. 전체 레이어의 무리의 중심으로 단일 포인트를 생성하는 대신, 산출 레이어가 각 범주에 있는 피처 무리의 중심을 담게 될 것입니다.
기본 메뉴:
23.1.12.11.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layer |
|
[vector: any] |
입력 벡터 레이어 |
Weight field 부가적 |
|
[tablefield: numeric] |
가중치를 적용한 평균을 작업하려는 경우 사용할 필드 |
Unique ID field |
|
[tablefield: numeric] |
평균을 계산할 유일 필드 |
Mean coordinates |
|
[vector: point] |
산출물을 저장할 (포인트 벡터) 레이어 |
23.1.12.11.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Mean coordinates |
|
[vector: point] |
산출되는 포인트(들) 레이어 |
23.1.12.11.3. 파이썬 코드¶
Algorithm ID: qgis:meancoordinates
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.12. 최근접 이웃 분석¶
포인트 레이어에 최근접 이웃 분석을 수행합니다. 산출물은 사용자 데이터가 어떻게 분포되었는지(군집되었는지, 랜덤한지, 또는 분포되었는지) 알려줍니다.
다음과 같은 계산된 통계 값을 가진 산출물을 HTML 파일로 생성합니다:
관측 평균 거리
기대 평균 거리
최근접 이웃 지수
포인트의 개수
Z-점수(Z-Score): 정규 분포와 Z-점수를 비교하면 사용자 데이터가 어떻게 분포되었는지 알 수 있습니다. 낮은 Z-점수는 데이터가 공간적으로 랜덤한 처리 과정의 결과일 가능성이 낮다는 의미이고, 높은 Z-점수는 사용자 데이터가 공간적으로 랜덤한 처리 과정의 결과일 가능성이 높다는 의미입니다.

기본 메뉴:
더 보기
23.1.12.12.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layer |
|
[vector: point] |
통계를 계산할 포인트 벡터 레이어 |
Nearest neighbour |
|
[html] |
계산된 통계를 가진 HTML 파일 |
23.1.12.12.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Nearest neighbour |
|
[html] |
계산된 통계를 가진 HTML 파일 |
Observed mean distance |
|
[number] |
관측 평균 거리 |
Expected mean distance |
|
[number] |
기대 평균 거리 |
Nearest neighbour index |
|
[number] |
최근접 이웃 지수 |
Number of points |
|
[number] |
포인트의 개수 |
Z-Score |
|
[number] |
Z점수(Z-Score) |
23.1.12.12.3. 파이썬 코드¶
Algorithm ID: qgis:nearestneighbouranalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.13. 중첩 분석¶
중첩 레이어에서 선택한 피처가 입력 레이어의 피처를 중첩하는 영역의 면적 및 커버 백분율을 계산합니다.
산출물 레이어에 중첩 레이어에서 선택한 각 피처가 입력 피처를 중첩하는 총 면적 및 커버 백분율을 보고하는 새 속성을 추가합니다.
23.1.12.13.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input layer |
|
[vector: any] |
입력 레이어 |
Overlap layers |
|
[vector: any] [list] |
중첩 레이어 |
Output layer |
|
[same as input] 기본값: |
산출 벡터 레이어를 지정합니다. 다음 가운데 하나로 저장할 수 있습니다:
이 파라미터에서 파일 인코딩도 변경할 수 있습니다. |
23.1.12.13.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Output layer |
|
[same as input] |
중첩 레이어에서 선택한 각 피처가 입력 피처를 중첩하는 (맵 단위) 총 면적 및 커버 백분율을 보고하는 새 속성을 추가한 산출 레이어 |
23.1.12.13.3. 파이썬 코드¶
Algorithm ID: qgis:overlapanalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.14. 범주 통계¶
필드의 통계를 부모 범주(parent class)에 따라 계산합니다. 부모 범주란 다른 필드들에서 나온 값을 조합한 것입니다.
23.1.12.14.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Input vector layer |
|
[vector: any] |
유일 범주 및 값을 가진 입력 벡터 레이어 |
Field to calculate statistics on (if empty, only count is calculated) 부가적 |
|
[tablefield: any] |
이 파라미터가 비어 있는 경우 개수만 계산할 것입니다. |
Field(s) with categories |
|
[vector: any] [list] |
(결합되어) 범주를 정의하는 필드들 |
Statistics by category |
|
[table] |
생성된 통계를 저장할 테이블 |
23.1.12.14.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Statistics by category |
|
[table] |
통계를 담고 있는 테이블 |
분석되는 필드의 유형에 따라, 각 그룹화된 값에 대해 다음 통계를 반환합니다:
통계 정보 |
문자열 |
수치 |
날짜 |
|---|---|---|---|
개수 ( |
|
|
|
유일 값 ( |
|
|
|
비어 있는 (NULL) 값 ( |
|
|
|
비지 않은 값 ( |
|
|
|
최소값 ( |
|
|
|
최대값 ( |
|
|
|
범위 ( |
|
||
합계 ( |
|
||
평균값 ( |
|
||
중간값 ( |
|
||
표준 편차 ( |
|
||
변동 계수 (coefficient of variation ─ |
|
||
소수 값 (가장 드물게 나오는 값 ─ |
|
||
다수 값 (가장 자주 나오는 값 ─ |
|
||
제1 사분위수 ( |
|
||
제3 사분위수 ( |
|
||
사분위수 범위 (제1 사분위수와 제3 사분위수 사이의 범위 ─ |
|
||
최단 길이 ( |
|
||
평균 길이 ( |
|
||
최장 길이 ( |
|

23.1.12.14.3. 파이썬 코드¶
Algorithm ID: qgis:statisticsbycategories
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.
23.1.12.15. 라인 길이 합계¶
폴리곤 레이어와 라인 레이어를 받아 각 폴리곤과 교차하는 라인 길이의 총합과 총 개수를 측정합니다.
입력 폴리곤 레이어와 동일한 피처를 가지면서, 각 폴리곤과 교차하는 라인의 길이와 개수를 담고 있는 새로운 두 속성을 추가한 레이어를 산출합니다.
기본 메뉴:
23.1.12.15.1. 파라미터¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Lines |
|
[vector: line] |
입력 라인 벡터 레이어 |
Polygons |
|
[vector: polygon] |
폴리곤 벡터 레이어 |
Lines length field name |
|
[string] 기본값: 〈LENGTH〉 |
라인 길이를 저장할 필드의 명칭 |
Lines count field name |
|
[string] 기본값: 〈COUNT〉 |
라인 개수를 저장할 필드의 명칭 |
Line length |
|
[vector: polygon] |
산출 폴리곤 벡터 레이어 |
23.1.12.15.2. 산출물¶
라벨 |
명칭 |
유형 |
설명 |
|---|---|---|---|
Line length |
|
[vector: polygon] |
라인 길이 및 개수 필드를 가진 산출 폴리곤 레이어 |
23.1.12.15.3. 파이썬 코드¶
Algorithm ID: qgis:sumlinelengths
import processing
processing.run("algorithm_id", {parameter_dictionary})
공간 처리 툴박스에 있는 알고리즘 위에 마우스를 가져가면 알고리즘 ID 를 표시합니다. 파라미터 목록(dictionary) 은 파라미터 명칭 및 값을 제공합니다. 파이썬 콘솔에서 공간 처리 알고리즘을 어떻게 실행하는지 자세히 알고 싶다면 콘솔에서 공간 처리 알고리즘 사용 을 참조하세요.