17.21. データ補完¶
ノート
この章では、ポイントデータの補完方法について示し、空間分析の実際の実行例を示します。
このレッスンでは、我々は、ラスタレイヤを得るためにポイントデータを補完します。その前に、我々は若干のデータ準備をしなければなりません、そして、補完後に、結果として生じるレイヤを修正するためにいくらかの余分の処理を加えるため、我々には完全な分析ルーチンがあります。
このレッスンの例となるデータを開くと、このように見えます。

現代の収穫者によって生み出されるように、データは収穫産出高データと一致します。そして、我々は収穫産出高のラスタレイヤを得るためにそれを使います。我々は、そのレイヤで更なる分析もしますが、ちょうど最も生産的な地域を簡単に特定するための背景レイヤ、更には生産性が改善されることができるものとして使うつもりはありません。
最初にやることは、ポイントが冗長なポイントを含むため、レイヤをクリーンアップすることです。それが何らかの理由で変更しなければならない、または変更する場所では、これらは収穫者の動きに起因します。*Points filter*アルゴリズムは、これに役立ちます。我々は二回それを使い、分布の上位または下位のパートの両方でアウトライアーとみなされるポイントを除外します。
最初の実行のため、次のパラメータ値を使います。
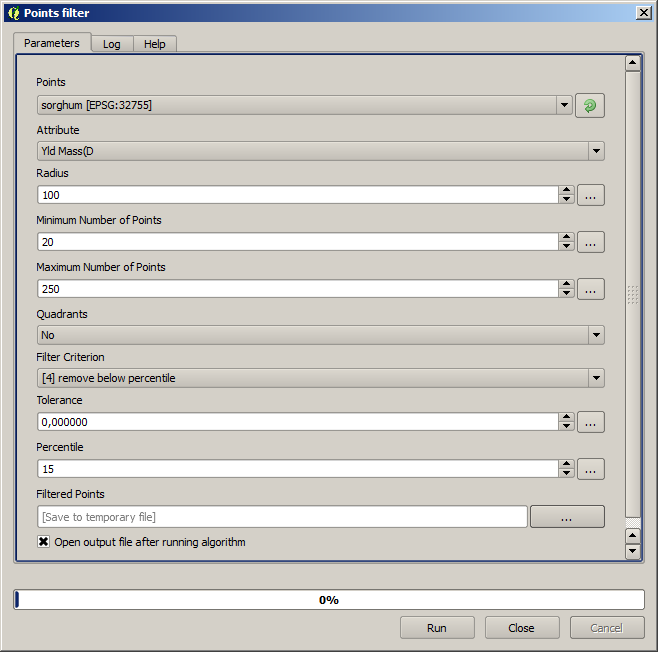
次の手順のため、以下に示す設定を使用します。
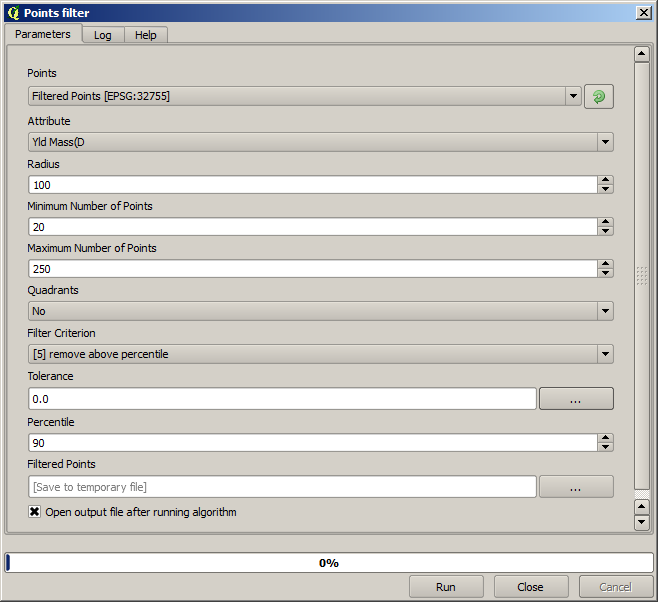
我々がオリジナルレイヤを入力して使っているが、それよりも前に実行した際の出力以外である点に注意してください。
最終的なフィルタレイヤはポイントのセットが減っていますが、オリジナルものと類似して見えます。しかしより少ないポイントを含みます。それらの属性テーブルで比較することで確認することができます。
Now let’s rasterize the layer using the Shapes to grid algorithm.
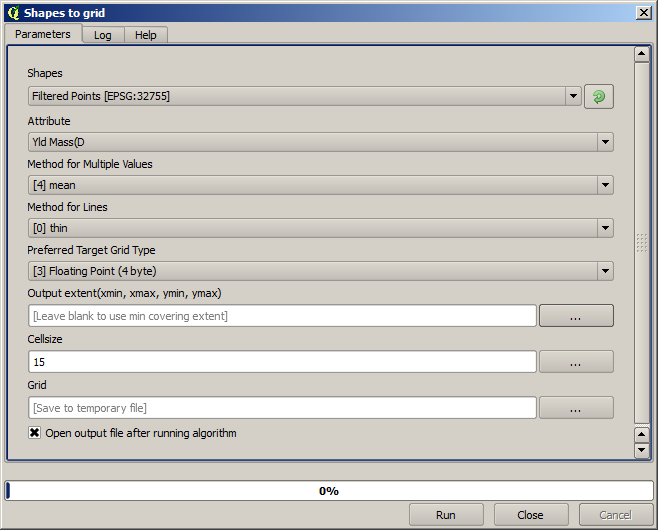
*Filtered points*レイヤは二番目のフィルタの1つを結果として参照します。それはアルゴリズムによって名前が指定されているため、最初のフィルタによって生成されたものと同じ名称を持ちますが、最初のものを使うべきではありません。我々が他の何かのためにそれを使っていないため、あなたは問題なく混乱を避けるプロジェクトからそれを取り除くことができて、最終的なフィルタ処理したレイヤを残すことができます。
結果のラスタレイヤはこのように見えます。

それはすでにラスタレイヤですが、一部のセルが欠落しています。ラスタライズしたベクタレイヤ由来のポイントとデータなし値を含むセルで有効な値のみを含みます。この欠損値を埋めるため、*Close gaps*アルゴリズムを使用することができます。
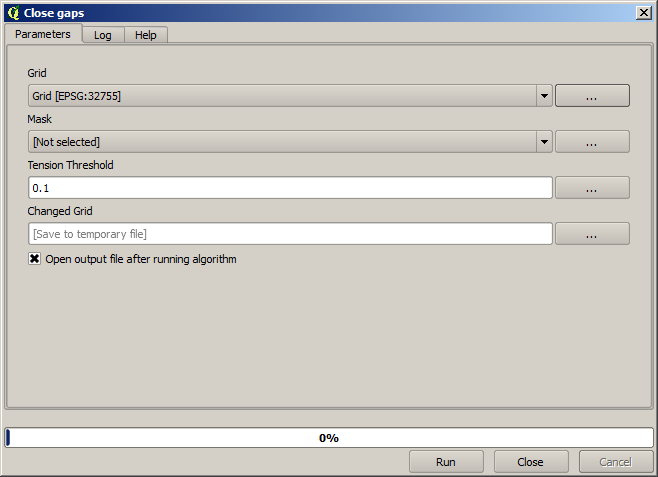
データなし値のないレイヤはこのように見えます。

収穫産出高が計られた地域において、データによっておおわれる地域を制限するために、我々は提供された制限レイヤでラスタレイヤを切り抜くことができます。
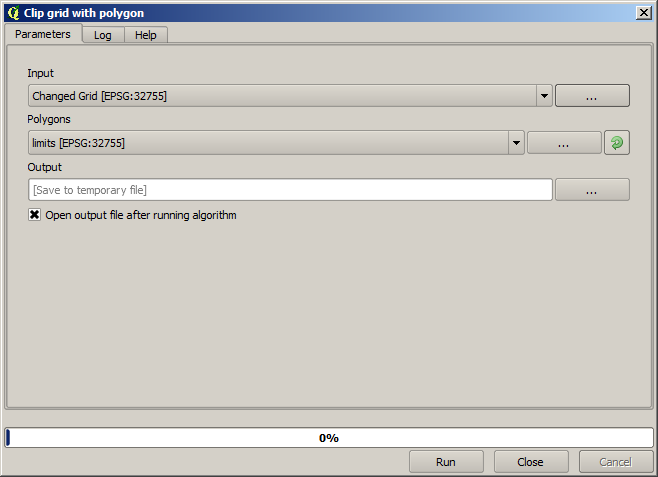
スムーズな結果(精度は低いがサポートレイヤとして背景にレンダリングされる)として、レイヤに*Gaussian filter*を適用します。
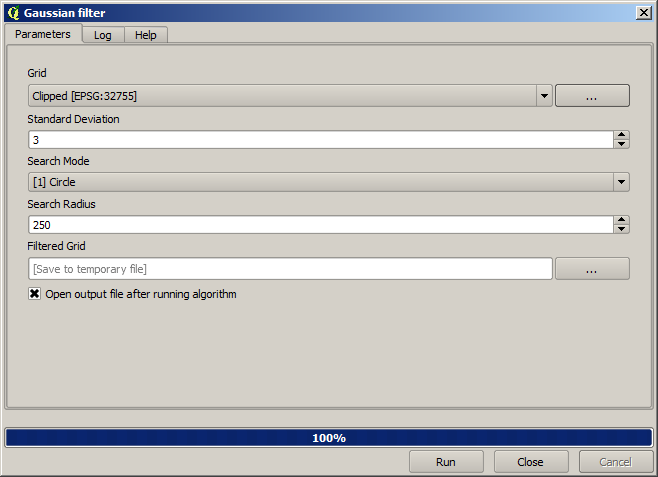
上記のパラメータで、次の結果が得られます。
