7.4. Lesson: Ruimtelijke statistieken¶
Notitie
Les ontwikkeld door Linfiniti en S Motala (Cape Peninsula University of Technology)
Ruimtelijke statistieken stellen u in staat te analyseren en te begrijpen wat er gaande is in een bepaalde vector gegevensset. QGIS bevat verschillende standaard gereedschappen voor statistische analyses die in dit opzicht hun nut hebben bewezen.
Het doel voor deze les: Weten hoe de ruimtelijke statistische gereedschappen in QGIS te gebruiken.
7.4.1.  Follow Along: Een test-gegevensset maken¶
Follow Along: Een test-gegevensset maken¶
We zullen een willekeurige verzameling van punten maken om een punt gegevensset te krijgen om mee te werken,
U heeft, om dat te doen, een polygoon gegevensset nodig die het bereik van het gebied waarin u de punten wilt maken definieert.
We zullen het gebied gebruiken dat wordt bedekt door straten.
Maak een nieuwe lege kaart.
Voeg uw laag
roads_34Stoe, als ook het rastersrtm_41_19.tif(hoogtegegevens) te vinden inexercise_data/raster/SRTM/.
Notitie
U zou kunnen merken dat uw laag SRTM DEM een ander CRS heeft dan die van de laag roads. Als dat zo is kunt u ofwel de laag roads of de laag DEM opnieuw projecteren met behulp van technieken die u eerder in deze module leerde.
Gebruik het gereedschap Convex hull(s) (beschikbaar onder Vector ‣ Geoprocessing-gereedschap) om een gebied te genereren dat alle wegen omvat:
Sla de uitvoer op onder
exercise_data/spatial_statistics/alsroads_hull.shp.Selecteer de optie Voeg resultaat toe aan kaartvenster om de uitkomst toe te voegen aan de inhoudsopgave (Lagenlijst).
7.4.1.1. Willekeurige punten genereren¶
Maak in dit gebied willekeurige punten met behulp van het gereedschap Vector ‣ Onderzoeks-gereedschap ‣ Willekeurige punten:

Sla de uitvoer op onder
exercise_data/spatial_statistics/alsrandom_points.shp.Selecteer de optie Voeg resultaat toe aan kaartvenster om de uitkomst toe te voegen aan de inhoudsopgave (Lagenlijst).

7.4.1.2. Een monster uit de gegevens¶
U moet de plug-in Point sampling tool gebruiken om een monster-gegevensset uit het raster te maken,.
Bekijk, indien nodig, de module over plug-ins.
Zoek naar de frase
point samplingin Plug-ins –> Beheer en installeer plug-ins... en u zult de plug-in vinden.Zodra het is geactiveerd met Plug-inbeheer, zult u het gereedschap vinden onder Plug-ins ‣ Analyses ‣ Point sampling tool:

Selecteer random_points als de laag die de monster-punten bevat en het SRTM-raster als de band waaruit de waarden moeten komen.
Zorg er voor dat “Add created layer to the TOC” is geselecteerd.
Sla de uitvoer op onder
exercise_data/spatial_statistics/alsrandom_samples.shp.
Nu kunt u de gegevens voor het monster uit het rasterbestand controleren in de attributentabel van de laag random_samples, zij zullen in een kolom, genaamd srtm_41_19.tif, staan.
Een mogelijke laag voor het monster wordt hier weergegeven:

De monster-punten worden door hun waarde geclassificeerd zodat donkere punten op een lagere hoogte liggen.
U zult deze monster-laag gaan gebruiken voor de rest van de statistische oefeningen.
7.4.2. Follow Along: Basisstatistieken¶
Nu nog de basisstatistieken voor deze laag ophalen.
Klik op het menu-item Vector ‣ Analyse-gereedschap ‣ Basisstatistieken.
Specificeer, in het dialoogvenster dat verschijnt, de laag:guilabel:random_samples als de bron.
Zorg er voor dat het Doelveld is ingesteld op
srtm_41_19.tifwat het veld is waarvoor u de statistieken wilt berekenen.Klik op OK. U krijgt resultaten zoals deze:

Notitie
U kunt de resultaten kopiëren en plakken in een werkblad. De gegevens gebruiken het scheidingsteken (dubbele punt :).

Sluit het dialoogvenster als het voltooid is.
Bekijk deze lijst met definities om de bovenstaande statistieken te begrijpen:
- Gemiddelde
De gemiddelde waarde is eenvoudigweg de som van de waarden, gedeeld door het aantal waarden.
- StdAfw:
De standaard afwijking. Geeft een indicatie over hoe dicht de waarden zijn geclusterd rondom het gemiddelde. Hoe kleiner de standaard afwijking, hoe meer waarden neigen naar het gemiddelde.
- Som
Alle waarden bij elkaar opgeteld.
- Min
De laagste waarde.
- Max
De hoogste waarde.
- N
Het aantal monsters/waarden.
- CV:
De ruimtelijke covariantie van de gegevensset.
- Aantal unieke waarden:
Het aantal waarden dat uniek is binnen de gegevensset. Als er 90 unieke waarden in een gegevensset met N=100, dan zijn de 10 resterende waarden hetzelfde als één of meer van de andere.
- Bereik
Het verschil tussen de laagste en de hoogste waarden.
- Mediaan
Als u alle waarden schikt van de laagste tot de hoogste, is de middelste waarde (of het gemiddelde van de twee middelste waarden als N een even getal is) de mediaan van de waarden.
7.4.3. Follow Along: Een afstandsmatrix berekenen¶
Maak een nieuwe puntenlaag in dezelfde projectie als de andere gegevenssets (
WGS 84 / UTM 34S).Ga naar modus Bewerken en digitaliseer drie punten ergens tussen de andere punten.
Gebruik, als alternatief, dezelfde methode voor het genereren van willekeurige punten als hiervoor, maar specificeer slechts drie punten.
Sla uw nieuwe laag op als
distance_points.shp.
Een afstandsmatrix genereren met behulp van deze drie punten:
Open het gereedschap Vector ‣ Analyse-gereedschap ‣ Distance matrix.
Selecteer de laag distance_points als de invoerlaag en de laag distance_points als de doellaag.
Stel het als volgt in:

Sla het resultaat op als
distance_matrix.csv.Klik op OK om de afstandsmatrix te genereren.
Open het in een werkbladprogramma om de resultaten te zien. Hier is een voorbeeld:

7.4.4. Follow Along: ‘Dichtstbijzijnde buur’-analyse¶
Een ‘Dichtstbijzijnde buur’-analyse uitvoeren:
Klik op het menu-item Vector ‣ Analyse-gereedschap ‣ ‘Nearest neighbour’-analyse.
Selecteer, in het dialoogvenster dat verschijnt, de laag random_samples en klik op OK.
De resultaten zullen verschijnen in het tekstvak van het dialoogvenster, bijvoorbeeld:

Notitie
U kunt de resultaten kopiëren en plakken in een werkblad. De gegevens gebruiken het scheidingsteken (dubbele punt :).
7.4.5. Follow Along: Gemiddelde coördinaten¶
De gemiddelde coördinaten van een gegevensset verkrijgen:
Klik op het menu-item Vector ‣ Analyse-gereedschap ‣ Gemiddelde coördinaten.
Specificeer, in het dialoogvenster dat verschijnt, random_samples als de invoerlaag, maar laat de optionele keuzen ongewijzigd.
Specificeer de uitvoerlaag als
mean_coords.shp.Klik op OK.
Voeg, indien gevraagd, de laag toe aan de Lagenlijst.
Laten we dit eens vergelijken met de centrale coördinaat van de polygoon die werd gebruikt om het willekeurige monster te maken.
Klik op het menu-item Vector ‣ Geometrie-gereedschappen ‣ Polygoon centroïde.
Selecteer, in het dialoogvenster dat verschijnt, roads_hull als de invoerlaag.
Sla het resultaat op als
center_point.Voeg de laag toe aan de Lagenlijst., indien daarnaar gevraagd.
Zoals u in het voorbeeld hieronder kunt zien vallen de gemiddelde coördinaten en het middelpunt van het gebruikte gebied (in oranje) niet noodzakelijkerwijze samen:

7.4.6. Follow Along: Histogrammen van afbeeldingen¶
Het histogram van een gegevensset geeft de verdeling van de waarden ervan weer. De eenvoudigste manier om dit in QGIS te demonstreren is via het histogram van een afbeelding, beschikbaar in het dialoogvenster Laag-eigenschappen van elke afbeeldingslaag.
Klik, in uw Lagenlijst, met rechts op de SRTM DEM-laag.
Selecteer Eigenschappen.
Kies de tab Histogram. U moet misschien op de knop Histogram herberekenen klikken om de grafiek te genereren. U zult een grafiek zien die de frequentie van de waarden in de afbeelding beschrijft.
U kunt dat als een afbeelding exporteren:

Selecteer de tab Metadata, u kunt meer gedetailleerde informatie bekijken binnen het vak Eigenschappen.
De gemiddelde waarde is 332.8, en de hoogste waarde is 1699! Maar deze waarden zijn niet zichtbaar in het histogram. Waarom niet? Dat komt omdat er maar zo weinig van zijn, vergeleken met de overvloed aan pixels met waarden onder het gemiddelde. Dat is ook waarom het histogram zich zo ver naar rechts uitstrekt, zelfs hoewel er geen zichtbare rode lijn is die de frequentie markeert van waarden hoger dan ongeveer 250.
Onthoud daarom dat een histogram u de verdeling van de waarden laat zien en dat niet alle waarden noodzakelijkerwijze ook zichtbaar zijn in de grafiek.
(U kunt nu Laag-eigenschappen sluiten.)
7.4.7. Follow Along: Ruimtelijke interpolatie¶
Laten we zeggen dat u een collectie monsterpunten heeft van waaruit u gegevens wilt extrapoleren. U heeft misschien toegang tot de gegevensset random_samples die we eerder gemaakt hebben en wil een idee krijgen over hoe het terrein eruit ziet.
Start, om te beginnen, het gereedschap Grid (Interpolatie) door te klikken op het menu-item Raster ‣ Analyse ‣ Grid (Interpolatie).
Selecteer
random_samples. in het veld Invoerbestand.Selecteer het vak Z-veld en selecteer het veld
srtm_41_19.Stel de locatie Uitvoerbestand in op
exercise_data/spatial_statistics/interpolation.tif.Selecteer het vak Algoritme en selecteer Inverse afstandweging.
Stel Macht in op
5.0en de Afvlakken op2.0. Laat de andere waarden zoals ze zijn.Selecteer het vak Na afloop in kaartvenster laden en klik op OK.
Wanneer het voltooid is, klik op OK in het dialoogvenster dat zegt
Verwerking voltooid, klik op OK in het dialoogvenster dat de informatie over de terugkoppeling weergeeft (als het is verschenen), en klik op Close in het dialoogvenster Grid (Interpolatie).
Hier is een vergelijking van de originele gegevensset (links) met die welke we hebben gemaakt uit onze monsterpunten (rechts). Die van u kan er anders uitzien vanwege de willekeurige herkomst van de locatie van de monsterpunten.

Zoals u kunt zien zijn 100 monsterpunten niet echt voldoende om een gedetailleerde impressie van het terrein te geven. Het geeft een heel algemeen idee, maar het kan ook misleidend zijn. In de afbeelding hierboven is het bijvoorbeeld niet duidelijk dat er een hoge ononderbroken bergrug van oost naar west loopt; in plaats daarvan lijkt de afbeelding een vallei met hoge pieken in het westen weer te geven. Met behulp van slechts een visuele inspectie kunnen we zien dat de monster-gegevensset niet representatief is voor het terrein.
7.4.8.  Try Yourself¶
Try Yourself¶
Gebruik de hierboven weergegeven processen om een nieuwe set van
1000willekeurige punten te maken.Gebruik die punten om een monster te nemen uit de originele DEM.
Gebruik het gereedschap Grid (Interpolatie) op deze nieuwe gegevensset, zoals hierboven.
Stel de bestandsnaam voor het uitvoerbestand in op
interpolation_1000.tif, met Macht en Afvlakken respectievelijk ingesteld op5.0en2.0.
De resultaten (afhankelijk van de positie van uw willekeurige punten) zal er min of meer zo uitzien:

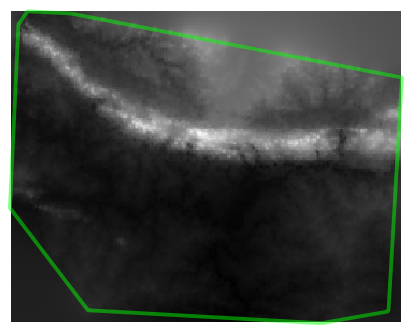
De rand geeft de laag roads_hull weer (wat de begrenzing van de willekeurige monsterpunten weergeeft) om het plotseling ontbreken van detail voorbij deze randen uit te leggen. Dit is al een veel betere weergave van het terrein, wegens de veel grotere dichtheid van de monsterpunten.
Hier is een voorbeeld van hoe het er uitziet met 10.000 monsterpunten:
Notitie
Het wordt niet aangeraden dat u dit probeert te doen met 10.000 monsterpunten als u niet werkt op een snelle computer, omdat de grootte van de monster-gegevensset heel veel verwerkingstijd vraagt.
7.4.9. Follow Along: Aanvullende gereedschappen voor ruimtelijke analyse¶
Van origine een afzonderlijk project en later toegankelijk als een plug-in, is de software SEXTANTE toegevoegd aan QGIS als een bronfunctie vanaf versie 2.0. U vindt het als een nieuw menu in QGIS onder zijn nieuwe naam Processing van waaruit u toegang krijgt tot een goed gevulde kist met gereedschappen voor ruimtelijke analyses, die u in staat stellen toegang te krijgen tot verschillende gereedschappen voor plug-ins met één enkele interface.
Activeer deze set van gereedschappen door het menu-item Processing ‣ Toolbox

U zult het waarschijnlijk vastgezet zien in QGIS aan de rechterkant van de kaart. Onthoud dat de hier vermelde gereedschappen koppelingen zijn naar de feitelijke gereedschappen. Sommige daarvan zijn SEXTANTE’s eigen algoritmes en andere zijn koppelingen naar gereedschappen van waar toegang wordt verkregen uit externe toepassingen zoals GRASS, SAGA of de Orfeo Toolbox. Deze externe toepassingen zijn tezamen met QGIS geïnstalleerd dus u kunt er al gebruik van maken. In het geval dat u de configuratie van de gereedschappen voor Processing moet wijzigen of, bijvoorbeeld, u moet bijwerken naar een nieuwe versie van een van de externe toepassingen, krijgt u toegang tot de instellingen ervan via Processing ‣ Opties en configuratie.
7.4.10. Follow Along: Analyse van ruimtelijke puntpatronen¶
Voor een eenvoudige indicatie van de ruimtelijke verdeling van punten in de gegevensset random_samples, kunnen we gebruik maken van SAGA’s gereedschap Spatial Point Pattern Analysis via de Processing Toolbox die u zojuist geopend heeft.
Zoek, in de Processing Toolbox,naar dit gereedschap Spatial Point Pattern Analysis.
Dubbelklik erop om het dialoogvenster ervan te openen.
7.4.10.1. SAGA installeren¶
Notitie
Als SAGA niet is geïnstalleerd op uw systeem, zal het dialoogvenster van de plug-in u informeren over het feit dat de afhankelijkheid ontbreekt. Als dat niet het geval is kunt u deze stappen overslaan.
7.4.10.2. Op Windows¶
Opgenomen in uw cursusmateriaal vindt u het installatieprogramma voor SAGA voor Windows.
Start het programma en volg de instructies ervan om SAGA op uw Windows-systeem te installeren. Onthoud het pad waaronder u het installeert!
Als u SAGA eenmaal heeft geïnstalleerd, dient u SEXTANTE te configureren om het pad te vinden waar het onder werd geïinstalleerd.
Klik op het menu-item Processing ‣ Opties en configuratie.
In het dialoogvenster dat verschijnt, vergroot het item SAGA en zoek naar SAGA folder. De waarde ervan zal leeg zijn.
Voer, in dit vak, het pad in waar u SAGA heeft geïnstalleerd.
7.4.10.3. Op Ubuntu¶
Zoek naar SAGA GIS in het Software Center, of voer de frase
sudo apt-get install saga-gisin uw terminal in. (U moet misschien eerst een SAGA-repository toevoegen aan uw bronnen.)QGIS zal SAGA automatisch vinden, alhoewel u misschien QGIS opnieuw moet starten als het niet direct werkt.
7.4.10.4. Op Mac¶
gebruikers van Homebrew kunnen SAGA installeren met deze opdracht:
- brew install saga-core
Als u Homebrew niet gebruikt, volg dan de instructies hieronder:
http://sourceforge.net/apps/trac/saga-gis/wiki/Compiling%20SAGA%20on%20Mac%20OS%20X
7.4.10.5. Na het installeren¶
Nu u SAGA heeft geïnstalleerd en geconfigureerd, zullen de functies ervan voor u toegankelijk zijn.
7.4.10.6. SAGA gebruiken¶
Open het dialoogvenster van SAGA.
SAGA produceert drie uitvoeren en zal daarom drie paden voor uitvoer nodig hebben.
Sla deze drie uitvoeren op onder
exercise_data/spatial_statistics/, onder bestandsnamen die u toepasselijk vindt.

De uitvoer zal er zo uitzien (de symbologie werd voor dit voorbeeld gewijzigd):

De rode punt is het gemiddelde middelpunt; de grote cirkel is de standaard afstand, wat een indicatie geeft van hoe dicht de punten zijn verdeeld rondom het gemiddelde middelpunt; en de rechthoek is het begrenzingsvak, dat de kleinst mogelijke rechthoek beschrijft die nog steeds alle punten omsluit.
7.4.11. Follow Along: Analyse minimum afstand¶
Vaak zal de uitvoer van een algoritme geen shapefile zijn, maar in plaats daarvan een tabel die een overzicht geeft van de statistische eigenschappen van een gegevensset. Eén hiervan is het gereedschap Minimum Distance Analysis.
Zoek dit gereedschap in de Processing Toolbox als :guilabel:`Minimum
Het vereist geen andere invoer dan het specificeren van de vector punten gegevensset die moet worden geanalyseerd.
Kies de gegevensset random_points.
Klik op OK. Na het voltooien zal een DBF-tabel verschijnen in de Lagenlijst.
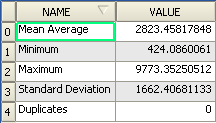
Selecteer die en open de attributentabel. Hoewel de getallen kunnen variëren, zullen uw resultaten in deze indeling zijn:
7.4.12. In Conclusion¶
QGIS heeft vele mogelijkheden voor het analyseren van de ruimtelijke statistische eigenschappen van gegevenssets.
7.4.13. What’s Next?¶
Nu we vectoranalyse hebben behandeld, waarom niet eens kijken wat er met rasters gedaan kan worden? Dat is wat we zullen gaan doen in de volgende module!