7.4. Lesson: 空間統計¶
ノート
Lesson developed by Linfiniti and S Motala (Cape Peninsula University of Technology)
空間統計では、分析し、与えられたベクタデータセットで何が起こっているかを理解することができます。 QGISは、この点で有用であることが分かる統計分析のためのいくつかの標準的なツールが含まれています。
**このレッスンの目標:**QGISの空間統計ツールの使い方を知ること。
7.4.1.  Follow Along: テストデータセットの作成¶
Follow Along: テストデータセットの作成¶
ポイントデータセットの操作を知るために、ポイントのランダムセットを作成します。
そのためには、ポイントを作成したいエリアの範囲を定義するポリゴンデータセットが必要です。
ストリートで覆われているエリアを使います。
空のマップを新規に開始します。
roads_34Sレイヤとexercise_data/raster/SRTM/にあるsrtm_41_19.tifraster (elevation data) を追加します。
ノート
あなたのSRTMのDEMレイヤは道路レイヤとは異なるCRSを持っていることがわかるかもしれません。その場合は、それ以前のこのモジュールの学んだ技術を使用して、道路またはDEMレイヤのいずれかを再投影することができます。
凸包 ツール(ベクタ ‣ ジオプロセシングツール で利用可能)を使用し、道路をすべて覆ったエリアを生成します。

- Save the output under
exercise_data/spatial_statistics/asroads_hull.shp. 結果をキャンバスに追加する オプションをチェックして、出力をTOC(レイヤーlist )に追加します。
7.4.1.1. ランダム点群の作成¶
ベクタ ‣ 調査ツール ‣ ランダム点群 ツールを使用して、このエリアにランダム点群を作成します。

exercise_data/spatial_statistics/以下にrandom_points.shpとして保存します。結果をキャンバスに追加する オプションをチェックして、出力をTOC(レイヤーlist )に追加します。

7.4.1.2. データのサンプリング¶
ラスタからサンプルデータセットを作成するため、 ポイントサンプルツール プラグインを使う必要があるでしょう。
必要に応じてプラグインで、モジュールを先に参照してください。
Plugin –> プラグインの管理とインストール... で
point samplingというフレーズで検索し、このプラグインを見つけます。プラグインマネージャ で有効化されたら、 プラグイン ‣ 分析 ‣ ポイントサンプリングツール を見つけることができます。

サンプル点群を含むレイヤを ランダム点群 として、SRTM ラスタを値を取得するバンドとして選択します。
“作成したレイヤをTOCに追加する”がチェックされていることを確認します。
exercise_data/spatial_statistics/以下にrandom_samples.shpを出力して保存します。
今、random_samples レイヤーの属性テーブル内でラスタファイルからサンプリングしたデータを確認できます、それらは名前|srtmFileName| の列にあります。
サンプルレイヤはここに示すとおりです:

より暗い点が低い高度であるように、サンプル点はそれらの値によって分類されます。
あなたは、残りの統計エクササイズのためにこのサンプルレイヤを使っています。
7.4.2. Follow Along: 基本統計¶
さて、このレイヤに対して基本統計を取得しましょう。
ベクトル->分析ツール->基本統計 メニューエントリをクリックします。
表示されたダイアログで、ソースとして random_samples レイヤーを指定します。
ターゲットフィールド が
srtm_41_19.tifに設定されていることを確認してください。これは統計を計算されるフィールドです。OK をクリックします。結果はこのようになります。

ノート
スプレッドシートに結果をコピーして貼り付けできます。データはセパレータ(コロン : )を使用します。

実行後はプラグインダイアログを閉じます。
上記の統計情報を理解するには、この定義のリストを参照してください。
- 平均
平均(平均)値は、単純な値の量で割った値の合計です。
- StdDev
標準偏差。値は平均値の周りにクラスタ化されているか、密接に指示を与えます。標準偏差が小さいほど、より近い値が平均値になる傾向があります。
- 合計
すべての値を加算します。
- 最小
値の最小値です。
- 最大
値の最大値です。
- N
サンプル/値の量です。
- CV
データセットの spatial covariance
- ユニークな値の数
このデータセット全体でユニークな値の数。N = 100のデータセットで90個のユニークな値がある場合、残りの10の値はどれかと同じです。
- レンジ
最小および最大値間の差です。
- 中間値
最小から最大までのすべての値を整列させた場合、真ん中の値(またはNが偶数である場合は真ん中の2つの値の平均)は値の中央値です。
7.4.3. Follow Along: 距離マトリクスの算出¶
他のデータセットと同じ投影で新しい点レイヤーを作成します(
WGS 84 / UTM 34S)。編集モードに入り、どこか他の点のうち3点をデジタル化。
あるいは、前と同じランダム点生成方法を使用するが、3点だけを指定します。
新規レイヤを
distance_points.shpとして保存します。
これらのポイントを使って距離マトリックスを生成します。
ベクトル->分析ツール->距離matrix ツールを開きます。
入力レイヤーとして distance_points レイヤー、ターゲットレイヤーとして random_samples レイヤーを選択します。
このように設定します:

- Save the result as
distance_matrix.csv. OK をクリックし、距離マトリックスを生成します。
結果を確認するには、スプレッドシートプログラムで開きます。次に例を示します。

7.4.4. Follow Along: 最小近傍分析¶
最小近傍分析を行うために:
ベクトル->分析ツール->最小近傍分析 メニュー項目をクリックします。
表示されるダイアログで、random_samples レイヤを選択し OK をクリックしてください。
結果は、たとえば、ダイアログのテキストウィンドウに表示されます。

ノート
スプレッドシートに結果をコピーして貼り付けできます。データはセパレータ(コロン : )を使用します。
7.4.5. Follow Along: 平均座標¶
データセットの平均座標を取得するために:
ベクター‐>分析ツール->平均座標 メニュー項目をクリックしてください。
表示されるダイアログで、入力レイヤーとして random_samples を指定しますが、オプションの選択肢はそのまま残します。
- Specify the output layer as
mean_coords.shp. - Click OK.
メッセージが表示されたら レイヤリスト に追加されます。
ランダムなサンプルを作成するために使用されたポリゴンの座標の中央にこれを比較してみましょう。
ベクトル->ジオメトリツール->ポリゴン重心 メニュー項目をクリックします。
表示されるダイアログで、入力レイヤーとして roads_hull を選択します。
- Save the result as
center_point. メッセージが表示されたら( Layers list ) に追加されます。
以下の例からもわかるように、平均座標と(オレンジ色)の研究領域の中心は必ずしも一致しません。

7.4.6. Follow Along: イメージヒストグラム¶
データセットのヒストグラムは、その値の分布を示しています。 任意の画像層のレイヤProperties ダイアログQGISでこれを実証するための最も簡単な方法はで利用可能な画像のヒストグラムを介してです。
レイヤーlist でSRTMのDEMレイヤーを右クリックします。
プロパティ を選択します。
ヒストグラム タブを選択します。 グラフィックを生成するには ヒストグラム計算 ボタンをクリックする必要があるかもしれません。画像内の値の度数を記述するグラフが表示されます。
それをイメージとして出力できます:
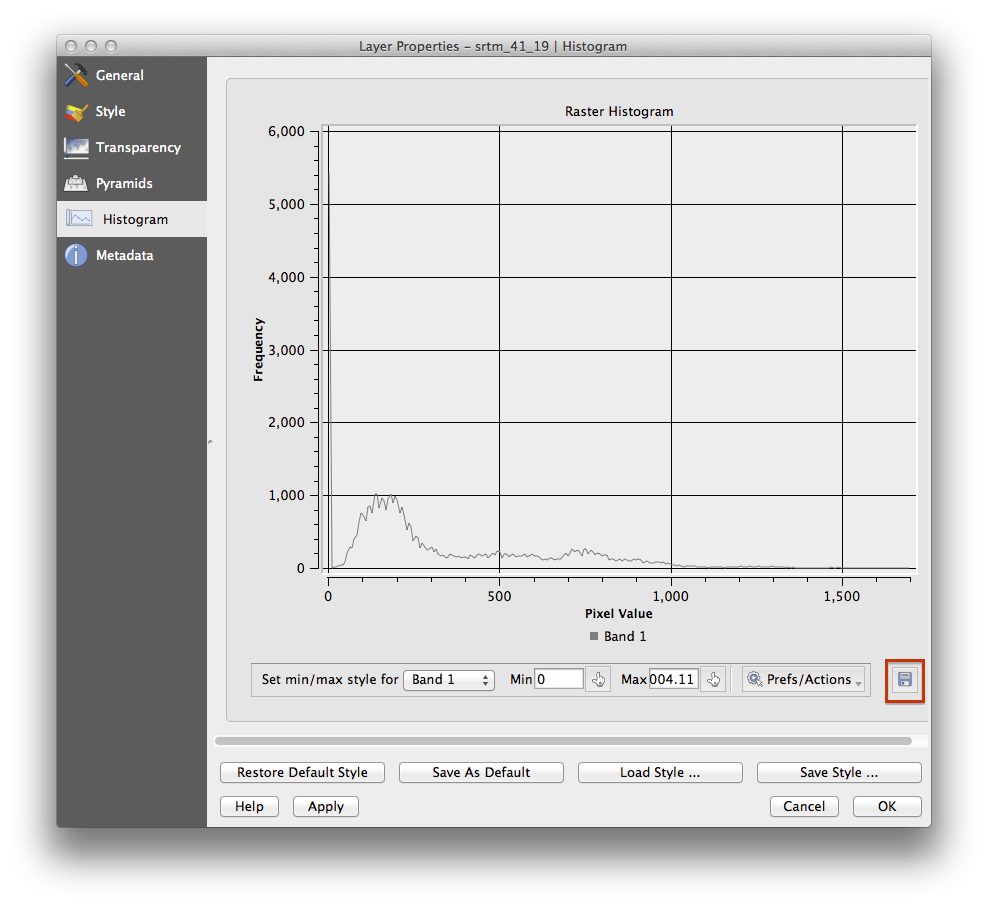
メタデータ タブを選択します。 プロパティ ボックスに、内部のより詳細な情報を見ることができます。
平均値は 332.8 で、最大値は 1699 です!しかし、これらの値はヒストグラムに表示されません。なぜ?これは、平均以下の値を持つピクセルが豊富にあるのに比べて、それらが非常に少ないためです。これもまた、およそ 250 より高い値の度数をマークする目に見える赤い線が存在しないにもかかわらず、ヒストグラムがここまで右に拡張した理由です。
ですから、ヒストグラムは値の分布を示しており、すべての値がグラフに必ずしも表示されているではないことを覚えておいてください。
(これで レイヤーProperties は閉じてかまいません。)
7.4.7. Follow Along: 空間的補間¶
データを推定したいと思い、そこからサンプル点のコレクションを持っているとしましょう。たとえば、以前に作成した random_samples データセットへのアクセス権を持っている、そして地形がどのように見えるかのいくつかのアイデアを持ちたいかもしれません。
開始するには、 ラスター->分析->グリッド(補間) メニュー項目をクリックして グリッド(補間) ツールを起動します。
入力ファイル フィールドで:kbd:random_samples を選択します。
Z Field ボックスをチェックし、:kbd:` srtm_41_19` フィールドを選択します。
出力ファイル 場所を:kbd:exercise_data/spatial_statistics/interpolation.tif に設定します。
アルゴリズム ボックスをチェックし、 逆二乗距離 を選択します。
- Set the Power to
5.0and the Smoothing to2.0. Leave the other values as-is. - Check the Load into canvas when finished box and click OK.
終わったら、
処理完了というダイアログで OK をクリックし、フィードバック情報を表示するダイアログで(現れた場合) OK をクリックし、 :guilabel: グリッド(補間) ダイアログで 閉じる をクリックします。
ここにあるのは元のデータセット(左)と私たちのサンプルポイントから構築されたもの(右)との比較です。あなたのはサンプル点の位置のランダムな性質のため異なっている場合があります。
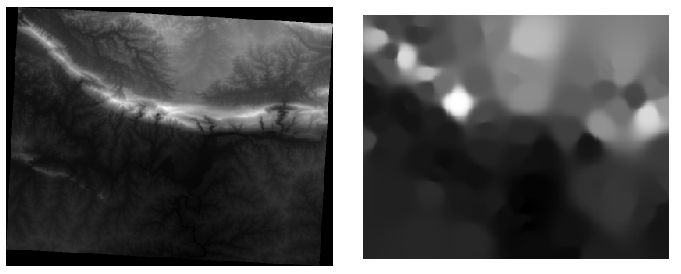
見ることができるように、サンプル100点では、地形の詳細な印象を受けるのは本当に十分ではありません。これは非常に一般的なアイデアを与えるが、それは同様に誤解を招くことができます。例えば、上記の画像では、東から西に実行高い、切れ目のない山があることは明らかではありません。むしろ、画像は西に高いピークと谷を、示しているようです。ただ目視検査を使用して、サンプルデータセットは、地形を表現していないことがわかります。
7.4.8.  Try Yourself¶
Try Yourself¶
上に示したプロセスを使用して、ランダムな
1000点の新しいセットを作成してください。オリジナルのDEMをサンプリングするためにこれらのポイントを使用してください。
上記のように、この新しいデータセットに グリッド(補間) ツールを使用します。
Power と Smoothing をそれぞれ
5.0、2.0と設定し、出力ファイル名をinterpolation_1000.tifに設定します。
結果(ランダムな点の位置に応じて)多かれ少なかれ、このようになります。

境界は、縁部を越えて突然詳細がなくなることを説明する roads_hull レイヤー(ランダムサンプル点の境界を表す)を示しています。これは、サンプル点の密度がはるかに大きいため、地形をより良く表現しています。
サンプル 10 000 点だとどのように見えるかの例です:

ノート
速いコンピュータで作業されていない場合は、サンプルデータセットのサイズは、処理に多くの時間を必要としますので、10000個のサンプル点でこれをやってみることはお勧めしません。
7.4.9. Follow Along: 追加の空間統計ツール¶
もともとは別のプロジェクト、その後はプラグインとしてアクセスできる、SEXTANTEソフトウェアはバージョン2.0からのコア機能としてQGISに追加されました。その新しい名前 :menuselection: Processing で新しいQGISメニューとして見つかります、そこからは空間分析ツールの豊富なツールボックスにアクセスでき、単一のインターフェース内からの様々なプラグインツールにアクセスできます。
処理->Toolbox メニューエントリを可能にすることにより、ツールのこのセットをアクティブにします。ツールボックスには、次のようになります。

おそらく、それはマップの右側にQGISにドッキング表示されます。ここに記載されているツールは、実際のツールへのリンクであることに注意してください。それらのいくつかはSEXTANTE独自のアルゴリズムであり、他には、GRASS、SAGAまたはオルフェオツールボックスなどの外部アプリケーションからアクセスされているツールへのリンクです。既にそれらを利用できるように、この外部アプリケーションは、QGISと一緒にインストールされています。処理ツールの設定を変更する必要があるか、例えば、外部アプリケーションの一つの新しいバージョンにアップデートする必要がある場合は、処理->オプションとconfigurations からその設定にアクセスできます。
7.4.10. Follow Along: 空間点パターン分析¶
random_samples データセット中のポイントの空間的な分布を簡単に表示するために 、たった今開いた 処理Toolbox 経由でSAGAの 空間ポイントパターンAnalysis ツールを利用できます。
処理Toolbox 中で、このツールを検索 空間ポイントパターンAnalysis 。
ダブルクリックしそのダイアログを開きます。
7.4.10.1. SAGAのインストール¶
ノート
SAGAがシステムにインストールされていない場合は、プラグインのダイアログによって依存関係が欠落していると通知されます。そうでない場合は、次の手順はスキップできます。
7.4.10.2. Windowsで¶
お使いの教材に含まれるものは、Windows用SAGAインストーラを見つけます。
プログラムを起動し、Windowsシステム上でSAGAをインストールするには、その指示に従ってください。インストールされているフォルダのパスをメモしてください!
SAGAをインストールしたら、それが下にインストールされたパスが見つかるようSEXTANTEを設定する必要があります。
メニュー項目:menuselection:分析 - > SAGAオプションとconfiguration をクリックしてください。
表示されたダイアログで、拡張:guilabel:SAGA アイテムを展開し、SAGAのfolder を探します。その値は空白になります。
このスペースに、SAGAをインストールしたパスを挿入します。
7.4.10.3. Ubuntu で¶
:guilabel:検索 でSAGAのGISソフトウェアCenter、または語句を入力しますが端末で:kbd: sudo apt-getを使用しているSAGAgisをインストール 。(まず自分のソースにSAGAリポジトリを追加する必要があります。)
それはすぐに動作しない場合は、QGISを再起動する必要があるかもしれませんが、QGISは、自動的にSAGAがあります。
7.4.10.4. Macで¶
自作ユーザーは、このコマンドでSAGAをインストールできます。
saga-coreのBREWインストール
自作を使用しない場合は、こちらの手順に従ってください。
http://sourceforge.net/apps/trac/saga-gis/wiki/Compiling%20SAGA20O%n%20Mac%20OS%20X
7.4.10.5. インストール後¶
今、インストールされSAGAが設定されていることを、その機能は、アクセスできるようになります。
7.4.10.6. SAGAの利用¶
SAGAダイアログを開きます。
SAGAは、3つの出力を生成し、したがって3つの出力経路を必要とします。
何でも適切と思うファイル名を使用して、
exercise_data / spatial_statistics/下にこれらの3つの出力を保存します。

出力は(記号は、この例のために変更された)次のようになります。

赤い点は平均中心です。大きな円は標準的距離で、点が平均中心の周りにどのくらい近くに分布しているかの指標を与えます。矩形はバウンディングボックスで、なおすべてのポイントを囲むであろう可能な最小の矩形を記述します。
7.4.11. Follow Along: 最小距離分析¶
多くの場合、このアルゴリズムの出力はシェープファイルではなく、データセットの統計的特性をまとめた表ではありません。これらの一つがある:guilabel:最小距離分析 ツール。
このツール:guilabel:処理Toolbox 中で:guilabel:最小距離Analysis として探します。
これは、分析されるベクタポイントデータセットを指定する以外に、他の入力を必要としません。
random_points データセットを選択します。
OK をクリックします。完了時に、DBFテーブルが:guilabel:レイヤーlist に表示されます。
それを選択し、その属性テーブルを開きます。数値はこれとは変わっている場合がありますが、結果はこの形式になります。

7.4.12. In Conclusion¶
QGISは、データセットの空間的な統計的性質を分析するための多くの可能性を可能にします。
7.4.13. What’s Next?¶
これでベクトル解析はカバーしましたが、ラスタで何ができるかは見ないのでしょうか。それは次のモジュールでやります!