24.1.13. Análisis vectorial¶
24.1.13.1. Estadísticas básicas para campos¶
Genera estadísticas básicas para un campo del atributo de la tabla de una capa vectorial.
Campos numérico, fecha, hora y texto son soportados.
Las estadísticas devueltas dependerán del tipo de campo.
Las estadísticas son generadas como un archivo HTML y están disponibles en .
Menú predeterminado:
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Vectorial de entrada |
|
[vectorial: cualquiera] |
Capa vectorial sobre la cuál calcular las estadíticas |
Campo para calcular las estadísticas |
|
[campo de tabla: cualquier] |
Cualquier campo de la tabla soportado para calcular las estadísticas |
Estadísticas |
|
[html] |
Archivo HTML para las estadísticas calculadas |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Estadísticas |
|
[html] |
Archivo HTML con las estadísticas calculadas |
Recuento |
|
[número] |
|
Número de valores únicos |
|
[número] |
|
Número de valores vacíos (nulos) |
|
[número] |
|
Número de valores no vacíos |
|
[número] |
|
Valor mínimo |
|
[la misma que la entrada] |
|
Valor máximo |
|
[la misma que la entrada] |
|
Longitud mínima |
|
[número] |
|
Longitud máxima |
|
[número] |
|
Longitud media |
|
[número] |
|
Coeficiente de variación |
|
[número] |
|
Suma |
|
[número] |
|
Valor promedio |
|
[número] |
|
Desviación estándar |
|
[número] |
|
Rango |
|
[número] |
|
Mediana |
|
[número] |
|
Minoría (valor de aparición mas rara) |
|
[la misma que la entrada] |
|
Mayoría (valor que sucede mas frecuentemente) |
|
[la misma que la entrada] |
|
Primer Cuartil |
|
[número] |
|
Tercer cuartil |
|
[número] |
|
Rango Intercuartil (IQR) |
|
[número] |
Código Python¶
Algoritmo ID: qgis:basicstatisticsforfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.2. Ascenso a lo largo de la línea¶
Calcula el ascenso y descenso total a lo largo de geometrías lineales. La capa de entrada debe tener valores Z presentes. Si los valores Z no están disponibles, el algoritmo Drapeado (establecer el valor Z del ráster) se puede usar para agregar valores Z de una capa MDE.
La capa de salida es una copia de la capa de entrada con campos adicionales que contienen el ascenso total (climb), el descenso total (descent), la elevación mínima (minelev) y la elevación máxima (maxelev) para cada geometría de línea. Si la capa de entrada contiene campos con los mismos nombres que estos campos agregados, se les cambiará el nombre (los nombres de los campos se modificarán a «name_2», «name_3», etc., encontrando el primer nombre no duplicado).
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa lineal |
|
[vectorial: lineal] |
Capa lineal sobre la cual calcular el ascenso. Debe tener valores Z |
Capa de ascenso |
|
[vectorial: lineal] |
La capa (lineal) saliente |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de ascenso |
|
[vectorial: lineal] |
Capa lineal contenedora de nuevos atributos con los resultados para los cálculos de ascenso. |
Ascenso total |
|
[número] |
La suma del ascenso para todas las geometrías lineales en la capa de entrada |
Descenso total* |
|
[número] |
La suma del descenso para todas las geometrías lineales en la capa de entrada |
Elevación mínima |
|
[número] |
La elevación mínima para las geometrías en la capa |
Elevación máxima |
|
[número] |
La elevación máxima para las geometrías de la capa |
Código Python¶
Algoritmo ID: qgis:climbalongline
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.3. Recuento de puntos en polígono¶
Toma una capa de puntos y una poligonal y cuenta el número de puntos de la capa de puntos en cada uno de los polígonos de la capa poligonal.
Se genera una nueva capa poligonal, con exactamente el mismo contenido que la capa poligonal entrante, pero conteniendo un camp adicional con el recuento de puntos que corresponden a cada polígono.
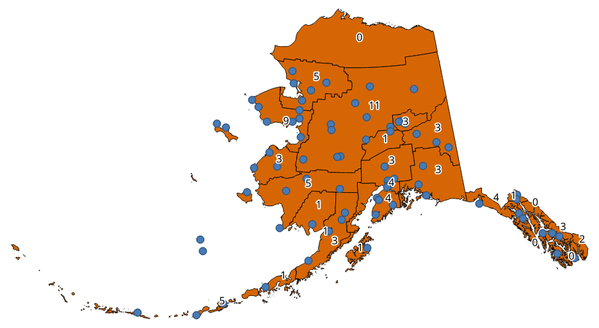
Figura 24.26 Las etiquetas en los polígonos muestran el recuento de puntos¶
Se puede utilizar un campo de peso opcional para asignar pesos a cada punto. Alternativamente, se puede especificar un campo de clase único. Si se utilizan ambas opciones, el campo de ponderación tendrá prioridad y el campo de clase única se ignorará.
Menú predeterminado:
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Polígonos |
|
[vectorial: polígonal] |
Capa poligonal cuyas entidades son asociadas con el número de puntos que contienen |
Puntos |
|
[vectorial: de puntos] |
Capa de puntos con objetos a contar |
Campo de peso Opcional |
|
[campo de tabla: cualquier] |
Un campo de la capa de puntos. El recuento generado será la suma del campo de pesos de los puntos que contiene el polígono. Si el campo de peso no es numérico, el recuento será |
Campo clase Opcional |
|
[campo de tabla: cualquier] |
Los puntos se clasifican según el atributo seleccionado y si varios puntos con el mismo valor de atributo están dentro del polígono, solo se cuenta uno de ellos. El conteo final de los puntos en un polígono es, por lo tanto, el conteo de las diferentes clases que se encuentran en él. |
Nombre del campo Recuento |
|
[cadena] Predeterminado: “NUMPOINTS” |
El nombre del campo donde almacenar el número de puntos |
Recuento |
|
[vectorial: polígonal] |
Especificación de la capa saliente |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Recuento |
|
[vectorial: polígonal] |
Capa resultante con la tabla de atributos conteniendo la nueva columna con el recuento de puntos |
24.1.13.4. Clustering o agrupamiento DBSCAN¶
Los clústeres señalan características basadas en una implementación 2D del algoritmo de agrupamiento espacial de aplicaciones con ruido (DBSCAN) basado en densidad.
El algoritmo requiere dos parámetros, un tamaño mínimo de grupo o cluster, y la distancia máxima entre puntos agrupados.
Ver también
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[vectorial: de puntos] |
Capa a analizar |
Tamaño mínimo de clúster |
|
[número] Predeterminado: 5 |
Número mínimo de objetos para generar un grupo |
Distancia máxima entre puntos agrupados |
|
[número] Predeterminado: 1.0 |
Distancia más allá de la cual dos entidades no pueden pertenecer al mismo grupo (eps) |
Nombre de campo de grupo |
|
[cadena] Predeterminado: “CLUSTER_ID” |
Nombre del campo donde se almacenará el número de grupo asociado |
Tratar los puntos fronterizos como ruido (DBSCAN*) Opcional |
|
[booleano] Predeterminado: False |
Si se marca, los puntos en el borde de un grupo se tratan como puntos no agrupados, y solo los puntos en el interior de un grupo se etiquetan como agrupados. |
Grupos |
|
[vectorial: de puntos] |
Capa vectorial para el resultado del agrupamiento |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Grupos |
|
[vectorial: de puntos] |
Capa vectorial que contiene las entidades originales con un campo que establece el grupo al que pertenecen |
Número de grupos |
|
[número] |
El número de grupos descubiertos |
Código Python¶
Algoritmo ID: qgis:dbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.5. Matriz distancia¶
Calcula distancias de entidades puntuales a las entidades más cercanas en la misma capa o en otra capa.
Menú predeterminado:
Ver también
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada de puntos |
|
[vectorial: de puntos] |
Capa de puntos para la cuál se calcula la matriz de distancia (desde puntos) |
Campo único ID de entrada |
|
[campo de tabla: cualquier] |
Campo que se utilizará para identificar de únicamente las entidades de la capa de entrada. Usado en la tabla de atributos de salida. |
Capa de puntos objetivo |
|
[vectorial: de puntos] |
Capa de puntos contenedora del punto(s) mas cercano a buscar(a puntos) |
Campo único ID objetivo |
|
[campo de tabla: cualquier] |
Campo a usar para identificar únicamente objetos de la capa objetivo. Usado en la tabla de atributos. |
Tipo de matriz saliente |
|
[enumeración] Predeterminado: 0 |
Diferentes tipos de cálculo están disponibles:
|
Usar solo los puntos objetivos (k) mas cercanos |
|
[número] Predeterminado: 0 |
Puede elegir calcular la distancia a todos los puntos en la capa de destino (0) o limitar a un número (k) de entidades más cercanas. |
Matriz de distancia |
|
[vectorial: de puntos] |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Matriz de distancia |
|
[vectorial: de puntos] |
Punto (o multipunto para el caso «Lineal (N * * k * x 3)») capa vectorial que contiene el cálculo de la distancia para cada entidad de entrada. Sus entidades y tabla de atributos dependen del tipo de matriz de salida seleccionado. |
Código Python¶
Algoritmo ID: qgis:distancematrix
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.6. Distancia al centro más cercano (línea a centro)¶
Crea líneas que unen cada entidad de un vector de entrada a la entidad más cercana en una capa de destino. Las distancias se calculan en base al centro de cada entidad.
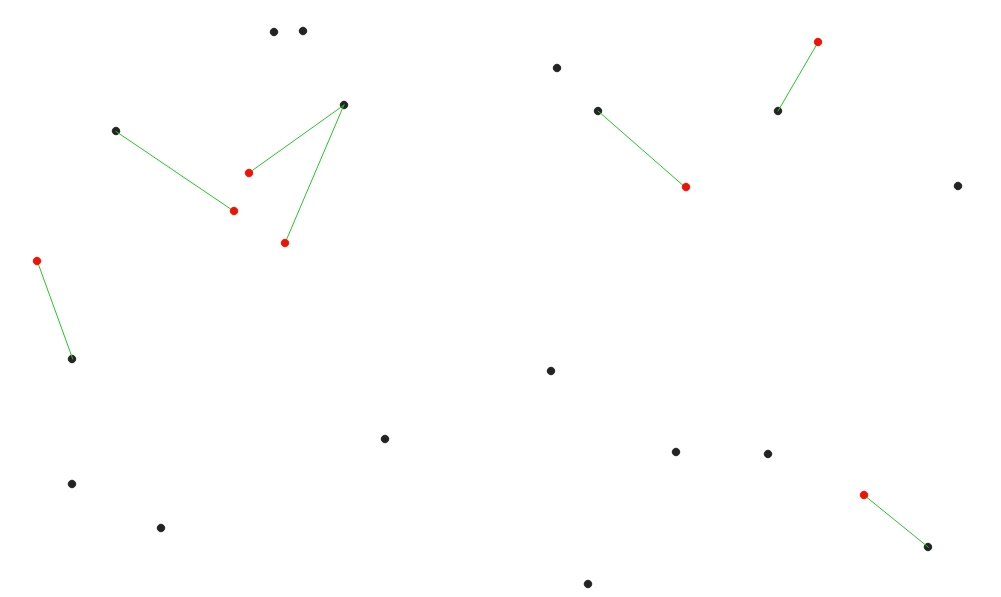
Figura 24.27 Mostrar el centro mas cercano para las entidades rojas entrantes¶
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de puntos fuente |
|
[vectorial: cualquiera] |
Capa vectorial para la cual se busca el objeto mas cercano |
Capa destino de centros |
|
[vectorial: cualquiera] |
Capa vectorial que contiene las entidades para buscar |
Nombre de atributo de capa de centro |
|
[campo de tabla: cualquier] |
Campo a usar para identificar unívocamente entidades de la capa de destino. Usado en la tabla de atributos saliente |
Unidad de medida |
|
[enumeración] Predeterminado: 0 |
Unidades en las cuales informar de la distancia a la entidad mas cercana:
|
Distancia al centro |
|
[vectorial: lineal] |
Capa lineal vectorial para la matriz distancia saliente |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Distancia al centro |
|
[vectorial: lineal] |
Capa vectorial lineal con los atributos de las entidades enteras, el identificador de su entidad mas cercana y la distancia calculada. |
Código Python¶
Algoritmo ID: qgis:distancetonearesthublinetohub
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.7. Distancia al centro mas cercano (puntos)¶
Crea una capa de puntos representando el centro de las entidades entrantes con dos campos añadidos conteniendo el identificador del objeto mas cercano (basado en su ponto central) y la distancia entre los puntos.
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de puntos fuente |
|
[vectorial: cualquiera] |
Capa vectorial para la cual se busca el objeto mas cercano |
Capa destino de centros |
|
[vectorial: cualquiera] |
Capa vectorial que contiene las entidades para buscar |
Nombre de atributo de capa de centro |
|
[campo de tabla: cualquier] |
Campo a usar para identificar unívocamente entidades de la capa de destino. Usado en la tabla de atributos saliente |
Unidad de medida |
|
[enumeración] Predeterminado: 0 |
Unidades en las cuales informar de la distancia a la entidad mas cercana:
|
Distancia al centro |
|
[vectorial: de puntos] |
Capa vectorial de puntos para la matriz distancia saliente. |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Distancia al centro |
|
[vectorial: de puntos] |
Capa de vector de puntos con los atributos de las entidades de entrada, el identificador de su entidad más cercana y la distancia calculada. |
Código Python¶
Algoritmo ID: qgis:distancetonearesthubpoints
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.8. Unión por líneas (líneas de centro)¶
Crea diagramas de centro y radios conectando líneas desde puntos en la capa Spoke a puntos coincidentes en la capa Hub.
La determinación de qué centro va con cada punto se basa en una coincidencia entre el campo de ID de centro en los puntos de centro y el campo de ID de radio en los puntos de radio.
Si las capas de entrada no son capas de puntos, se tomará un punto en la superficie de las geometrías como ubicación de conexión.
Opcionalmente, se pueden crear líneas geodésicas, que representan la ruta más corta en la superficie de un elipsoide. Cuando se utiliza el modo geodésico, es posible dividir las líneas creadas en el antimeridiano (± 180 grados de longitud), lo que puede mejorar la representación de las líneas. Además, se puede especificar la distancia entre vértices. Una distancia menor da como resultado una línea más densa y precisa.
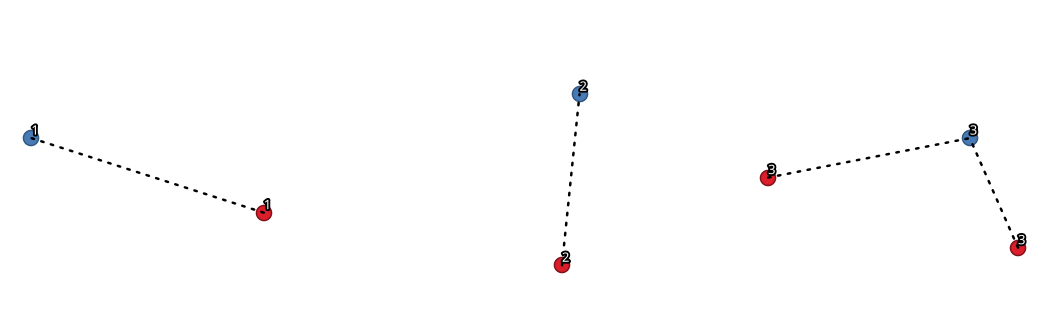
Figura 24.28 Unir puntos basados en un campo / atributo común¶
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa centro |
|
[vectorial: cualquiera] |
Capa entrante |
Campo ID centro |
|
[campo de tabla: cualquier] |
Campo de la capa de centros con la ID a unir |
**Campos de la capa centro a copiar (dejar vacío para copiar todos los campos)* Opcional |
|
[campo de tabla: cualquiera] [lista] |
El campo(s) de la capa central que se copiará. Si no se elige ningún campo(s), se toman todos los campos. |
Capa radios |
|
[vectorial: cualquiera] |
Capa de puntos adicional de radios |
Campo ID radio |
|
[campo de tabla: cualquier] |
Campo de la capa de radios con ID a unir |
Campos de la capa de radios a copiar (dejar vaciá para copiar todos los campos) Opcional |
|
[campo de tabla: cualquiera] [lista] |
Campo(s) de la capa de radios a copiar. Si no hay campos escogidos se toman todos los campos. |
Crear líneas geodésicas |
|
[booleano] Predeterminado: False |
Crear líneas geodésicas (la ruta mas corta en la superficie de un elipsoide) |
Distancia entre vértices (solo líneas geodésicas) |
|
[número] Predeterminado: 1000.0 (kilometros) |
Distancia entre vértices consecutivos (en kilómetros). Una distancia menor se traduce en una línea mas densa, mas precisa |
Cortar líneas al antimeridiano (±180 grados de longitud) |
|
[booleano] Predeterminado: False |
Cortar líneas a longitud ±180 grados (para mejorar la representación de las líneas) |
Líneas de centro |
|
[vectorial: lineal] |
La capa lineal resultante |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Líneas de centro |
|
[vectorial: lineal] |
La capa lineal resultante |
Código Python¶
Algoritmo ID: qgis:hublines
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.9. Agrupación de K-medias¶
Calcula el número de clúster de k-medias basado en la distancia 2D para cada entidad de entrada.
La agrupación en clústeres de K-medias tiene como objetivo dividir las entidades en k grupos en los que cada entidad pertenece al grupo con la media más cercana. El punto medio está representado por el baricentro de las entidades agrupadas.
Si las geometrías de entrada son líneas o polígonos, la agrupación se basa en el centroide de la entidad.
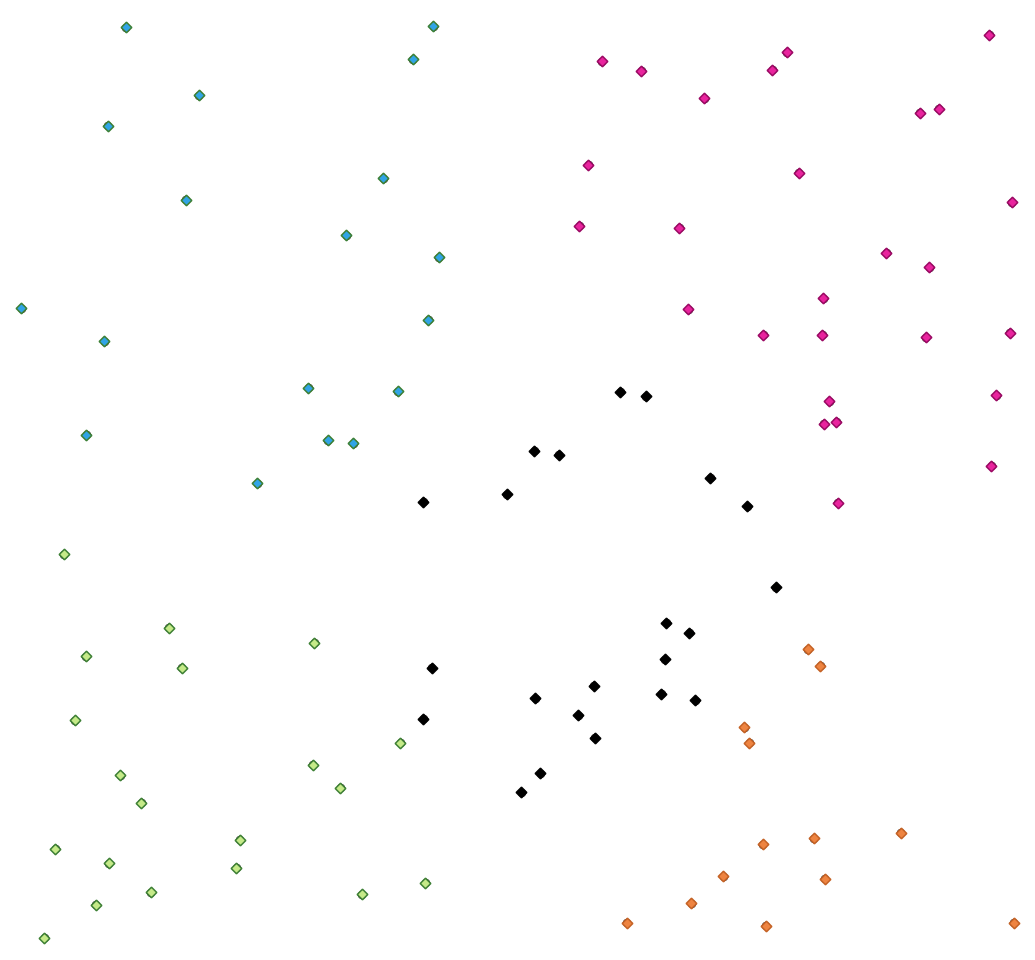
Figura 24.29 Un grupo de cinco puntos de clase¶
Ver también
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[vectorial: cualquiera] |
Capa a analizar |
Número de grupos |
|
[número] Predeterminado: 5 |
Número de grupos a crear con los objetos. |
Nombre de campo de grupo |
|
[cadena] Predeterminado: “CLUSTER_ID” |
Nombre del campo de número de grupo |
Grupos |
|
[vectorial: cualquiera] |
Capa vectorial para los grupos generados |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Grupos |
|
[vectorial: cualquiera] |
Capa vectorial que contiene las entidades originales con un campo que especifica el grupo al que pertenecen |
Código Python¶
Algoritmo ID: qgis:kmeansclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.10. Lista de valores únicos¶
Lista de valores únicos de un campod e la tabla de atributos y recuento de sus números.
Menú predeterminado:
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[vectorial: cualquiera] |
Capa a analizar |
Campo(s) destino |
|
[campo de tabla: cualquier] |
Campo a analizar |
Valores únicos |
|
[tabla] |
Resumen de tabla de capa con valores únicos |
Informe HTML |
|
[html] |
informe HTML de valores únicos en |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valores únicos |
|
[tabla] |
Resumen de tabla de capa con valores únicos |
Informe HTML |
|
[html] |
Informe HTML de valores únicos. Puede ser abierto desde |
Total de valores únicos |
|
[número] |
El número de valores únicos en el campo entrante |
UNIQUE_VALUES |
|
[cadena] |
Una cadena con la lista separada por comas de valores únicos que se encuentran en el campo de entrada |
Código Python¶
Algoritmo ID: qgis:listuniquevalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.11. Coordenada(s) Media¶
Calcula una capa de puntos con el centro de masa de geometrías en una capa de entrada.
Se puede especificar que un atributo contenga pesos que se aplicarán a cada entidad al calcular el centro de masa.
Si se selecciona un atributo en el parámetro, las entidades se agruparán según los valores de este campo. En lugar de un solo punto con el centro de masa de toda la capa, la capa de salida contendrá un centro de masa para las entidades en cada categoría.
Menú predeterminado:
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[vectorial: cualquiera] |
Capa de vector de entrada |
Campo de peso Opcional |
|
[campo de tabla: numérico] |
Campo a usar si quieres realizar una media ponderada |
Campo de ID único |
|
[campo de tabla: numérico] |
Campo único sobre el que se realizará el cálculo de la media |
Coordenadas medias |
|
[vectorial: de puntos] |
La capa (vector de puntos) para el resultado |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Coordenadas medias |
|
[vectorial: de puntos] |
Capa de punto(s) resultante |
Código Python¶
Algoritmo ID: qgis:meancoordinates
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.12. Análisis de vecino mas próximo¶
Realiza análisis de vecinos más cercanos para una capa de puntos. La salida le dice cómo se distribuyen sus datos (agrupados, aleatoriamente o distribuidos).
La salida se genera como un archivo HTML con los valores estadísticos calculados:
Distancia media observada
Distancia media esperada
Índice de vecino mas próximo
Número de puntos
Z-Score: comparar el Z-Score con la distribución normal le indica cómo se distribuyen sus datos. Un Z-Score bajo significa que es poco probable que los datos sean el resultado de un proceso espacialmente aleatorio, mientras que un Z-Score alto significa que es probable que sus datos sean el resultado de un proceso espacialmente aleatorio.

Menú predeterminado:
Ver también
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[vectorial: de puntos] |
Capa vectorial de puntos para calcular las estadísticas |
Vecino mas próximo |
|
[html] |
Archivo HTML para las estadísticas calculadas |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Vecino mas próximo |
|
[html] |
Archivo HTML con las estadísticas calculadas |
Distancia media observada |
|
[número] |
Distancia media observada |
Distancia media esperada |
|
[número] |
Distancia media esperada |
Índice de vecino más cercano |
|
[número] |
Índice de vecino mas próximo |
Número de puntos |
|
[número] |
Número de puntos |
Z-Score |
|
[número] |
Z-Score |
Código Python¶
Algoritmo ID: qgis:nearestneighbouranalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.13. Análisis de superposición¶
Calcula el área y el porcentaje de cobertura mediante el cual las entidades de una capa de entrada se superponen con las entidades de una selección de capas superpuestas.
Se agregan nuevos atributos a la capa de salida que informan el área total de superposición y el porcentaje de la entidad de entrada superpuesta por cada una de las capas de superposición seleccionadas.
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[vectorial: cualquiera] |
La capa entrante. |
Superposición de capas |
|
[vector: any] [list] |
Las capas superpuestas. |
Capa saliente |
|
[la misma que la entrada] Predeterminado: |
Especifica la capa vectorial saliente. Una de:
El fichero codificado también puede ser cambiado aquí. |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa saliente |
|
[la misma que la entrada] |
La capa de salida con campos adicionales que informan la superposición (en unidades de mapa y porcentaje) de la entidad de entrada superpuesta por cada una de las capas seleccionadas. |
Código Python¶
ID Algoritmo: qgis:calculatevectoroverlaps
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.14. Estadísticas por categorías¶
Calcula las estadísticas de un campo en función de una clase principal. La clase principal es una combinación de valores de otros campos.
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa vectorial entrante |
|
[vectorial: cualquiera] |
Capa vectorial de entrada con clases y valores únicos |
Campo para calcular estadísticas (si está vacío, solo se calcula el recuento) Opcional |
|
[campo de tabla: cualquier] |
Si está vacío solo se calcula el recuento |
Campo(s) con categorías |
|
[vector: any] [list] |
Los campos que (combinados) definen las categorías |
Estadísticas por categoría |
|
[tabla] |
Tabla para las estadísticas generadas |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Estadísticas por categoría |
|
[tabla] |
Tabla contenedora de las estadísticas |
Dependiendo del tipo del campo siendo analizado, las siguientes estadísticas son devueltas para cada valor de grupo:
Estadísticas |
Cadena |
Numérico |
Fecha |
|---|---|---|---|
Recuento ( |
|
|
|
Valores únicos ( |
|
|
|
Valores vacíos (nulos) ( |
|
|
|
Valores no vacíos ( |
|
|
|
Valor mínimo ( |
|
|
|
Valor máximo ( |
|
|
|
Rango ( |
|
||
Suma ( |
|
||
Valor medio( |
|
||
Valor mediana ( |
|
||
Desviación Estándar ( |
|
||
Coeficiente de variación ( |
|
||
Minoría (valor suceso mas raro - |
|
||
Mayoría (valor suceso mas frecuente - |
|
||
Primer cuartil ( |
|
||
Tercer cuartil ( |
|
||
Rango Inter Cuartil ( |
|
||
Longitud Mínima ( |
|
||
Longitud Media ( |
|
||
Longitud Máxima ( |
|

Código Python¶
Algoritmo ID: qgis:statisticsbycategories
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.
24.1.13.15. Suma de la longitud de las líneas¶
Toma una capa poligonal y una capa lineal y mide la longitud total de líneas y el número total de ellas que cruzan cada polígono.
La capa resultante tiene los mismos objetos que la capa poligonal entrante, pero con dos atributos adicionales conteniendo la longitud y el recuento de las líneas que cruzan cada polígono.
Menú predeterminado:
Parámetros¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Líneas |
|
[vectorial: lineal] |
Capa vectorial lineal entrante |
Polígonos |
|
[vectorial: polígonal] |
Capa vectorial poligonal |
Nombre de campo de la longitud de líneas |
|
[cadena] Predeterminado: “LENGTH” |
Nombre del campo para la longitud de las líneas |
Nombre de campo del recuento de líneas |
|
[cadena] Predeterminado: “COUNT” |
Nombre del campo para el recuento de líneas |
Longitud de Línea |
|
[vectorial: polígonal] |
La capa vectorial poligonal saliente |
Salidas¶
Etiqueta |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Longitud de Línea |
|
[vectorial: polígonal] |
Capa poligonal saliente con campos de longitud y recuento de líneas |
Código Python¶
Algoritmo ID: qgis:sumlinelengths
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra cuando pasa el cursor sobre el algoritmo en la caja de herramientas de procesos. El diccionario de parámetros proporciona los NOMBRES y valores de los parámetros. Consulte Utilizar algoritmos de procesamiento desde la consola para obtener detalles sobre cómo ejecutar algoritmos de procesamiento desde la consola de Python.