7.4. Lesson: Statistiques Spatiales¶
Note
Leçon développée par Linfiniti et S Motala (Cape Peninsula University of Technology)
Les statistiques spatiales vous permettent d’analyser et de comprendre ce qu’il se passe dans un jeu de données vectorielles. QGIS comprend plusieurs outils standards pour l’analyse statistique qui s’avèrent utiles à cet égard.
L’objectif de cette leçon: Apprendre à utiliser les outils de statistiques spatiales dans QGIS.
7.4.1.  Follow Along: Créer un jeu de données test¶
Follow Along: Créer un jeu de données test¶
Afin de disposer d’un jeu de données de type point à utiliser, nous allons créer un jeu de points au hasard.
Pour ce faire, vous aurez besoin d’un jeu de données de type polygone qui définira l’étendue de la zone dans laquelle vous voulez créer les points.
Nous allons utiliser l’emprise couverte par les rues.
Créer une nouvelle carte vide
Ajoutez votre couche
roads_34S, ainsi que le rastersrtm_41_19.tif(données d’élévation) trouvé sousexercise_data/raster/SRTM/.
Note
Vous pourriez trouver que votre couche SRTM MNE a un SCR différent que celui de la couche des routes. Si c’est le cas, vous pouvez reprojeter soit les routes soit la couche MNE en utilisant les techniques apprises plus tôt dans ce module.
Utilisez l’outil Enveloppe(s) Convexe(s) (disponible dans Vecteur ‣ Outils de géotraitement) pour générer une zone englobant toutes les routes:

Enregistrez le fichier de sortie sous
roads_hull.shpdans le dossierexercise_data/spatial_statistics/.Cochez l’option Ajouter le résultat au canevas afin d’avoir la couche dans la légende de carte (Panneau Couche)
7.4.1.1. Création de points aléatoires¶
Créer des points aléatoires dans cette zone à l’aide de l’outil Vecteur ‣ Outils de recherche ‣ Points aléatoires:
Enregistrez le fichier de sortie sous
random_points.shpdans le dossierexercise_data/spatial_statistics/.Cochez l’option Ajouter le résultat au canevas afin d’avoir la couche dans la légende de carte (Panneau Couche)

7.4.1.2. Échantillonage des données¶
Pour créer un simple jeu de données depuis le raster, vous devrez utiliser l’extension Point sampling tool.
Si nécessaire, consultez auparavant le module sur les extensions.
Recherchez le texte
point samplingdans la fenêtre Extension –> Installer/Gérer les extensions... et vous trouverez l’extension.Une fois activé dans le Gestionnaire d’extensions, vous verrez apparaître l’outil sous Extension ‣ Analyses ‣ Point sampling tool:

Sélectionnez la couche random_points qui contiendra l’échantillon de points et le raster SRTM comme bande depuis laquelle les données seront extraites.
Soyez sûr que “Ajouter la couche créée à la table des matières” est coché.
Enregistrez le fichier de sortie sous
random_samples.shpdans le dossierexercise_data/spatial_statistics/.
Maintenant vous pouvez vérifier que les données du fichier raster dans la table d’attributs de la couche random_samples, elles seront affichées dans la colonne nommée srtm_41_19.tif.
Voici un exemple de représentation de la couche:

Les points sont classifiés par leur valeur, les points sombres sont à basse altitude.
Vous allez utiliser cette couche d’échantillon pour le reste des exercices statistiques.
7.4.2. Follow Along: Statistiques Basiques¶
Maintenant, récupérez les statistiques basiques de cette couche.
Cliquez sur l’entrée du menu Vecteur ‣ Outils d’analyse ‣ Statistiques basiques.
Dans la fenêtre qui apparaît, indiquez la couche random_samples comme couche en entrée.
Assurez-vous que Champ cible contienne
srtm_41_19.tif, il s’agit du champ sur lequel seront calculées les statistiques.Cliquez sur OK. Vous obtiendrez des résultats comme ceci:

Note
Vous pouvez copier et coller les résultats dans un tableur. La donnée utilise le séparateur deux-points (:).

Une fois fait, fermez la fenêtre de l’extension.
Pour comprendre les statistiques ci-dessus, référez-vous à la liste de définition:
- Moyenne
La valeur moyenne est simplement la somme des valeurs divisée par le nombre de valeurs.
- Écart-type
La déviation standard. Donne une indication sur la manière dont les valeurs sont regroupées autour de la moyenne. Plus la déviation est faible, plus les valeurs tendent à se situer à la moyenne.
- Somme
Toutes les valeurs ajoutées ensemble.
- Min
La valeur minimale.
- Max
La valeur maximale.
- N
Le nombre de données/valeurs.
- CV
La covariance spatiale du jeu de données.
- Nombre de valeurs uniques
Le nombre de valeurs uniques dans l’ensemble du jeu de données. S’il y a 90 valeurs uniques dans un jeu de données ayant N=100, alors les 10 valeurs restantes sont identiques à une ou plusieurs d’entre elles.
- Portée
La différence entre les valeurs minimale et maximale.
- Médiane
Si vous ordonnez les valeurs de la plus petite à la plus grande, la valeur du milieu (ou la moyenne des deux valeurs du milieu si N est un nombre pair) est la médiane des valeurs.
7.4.3. Follow Along: Calculer une Matrice des Distances¶
Créez une nouvelle couche de point dans la même projection que les autres jeux de données (
WGS 84 / UTM 34S).Passez en mode Édition et numérisez trois points quelque part au milieu des autres points.
Utilisez la même méthode de génération de points aléatoires que précédemment mais indiquer seulement trois points.
Sauvegardez votre nouvelle couche sous
distance_points.shp.
Pour générer une matrice des distances utilisant ces points:
Ouvrez l’outil Vecteur ‣ Outils d’analyse ‣ Matrice des distances.
Sélectionnez la couche distance_points comme couche d’entrée et la couche random_samples comme couche cible.
Définissez-le comme ceci:

Sauvegardez le résultat sous
distance_matrix.csv.Cliquez sur OK pour générer la matrice des distances.
Ouvrez-le dans un tableur pour voir les résultats. Voici un exemple:
7.4.4. Follow Along: Analyse du Plus Proche Voisin¶
Pour faire une analyse du plus proche voisin:
Cliquez sur l’entrée du menu Vecteur ‣ Outils d’analyse ‣ Analyse du plus proche voisin.
Dans la fenêtre qui apparaît, sélectionnez la couche random_samples et cliquez sur OK.
Les résultats apparaîtront dans la boîte de dialogue de la fenêtre, comme sur l’exemple:

Note
Vous pouvez copier et coller les résultats dans un tableur. La donnée utilise le séparateur deux-points (:).
7.4.5. Follow Along: Coordonnées Moyennes¶
Pour obtenir les coordonnées moyennes d’un jeu de données:
Cliquez sur l’entrée du menu Vecteur ‣ Outils d’analyse ‣ Cordonnée(s) moyenne(s)
Dans la fenêtre qui apparaît, indiquez la couche random_samples comme couche en entrée, mais laissez inchangées les autres options.
Indiquez la couche de sortie:
mean_coords.shp.Cliquez sur OK.
Ajoutez la couche à la Légende de la carte quand demandé.
Comparons cela aux coordonnées centrales du polygone qui a été utilisé pour créer les données aléatoires.
Cliquez sur l’élément du menu Vecteur ‣ Outils de géométrie ‣ Centroïdes de polygones
Dans la fenêtre qui apparaît, indiquez la couche roads_hull comme couche en entrée.
Sauvegardez le résultat sous
center_point.Ajoutez-le dans la Légende de la carte lorsque demandé.
Comme vous pouvez le voir dans l’exemple ci-dessous, les coordonnées moyennes et le centroïde de la zone d’étude (en orange) ne coïncident pas nécessairement:

7.4.6. Follow Along: Histogrammes d’image¶
L’histogramme d’un jeu de données montre la distribution des valeurs. Le moyen le plus simple de l’afficher dans QGIS est d’utiliser l’historgramme d’image disponible dans la boîte de dialogue Propriétés de la couche de n’importe quelle couche d’image.
Dans votre Légende de la carte, faites un clic-droit sur la couche SRTM MNE.
Sélectionnez Propriétés.
Choisissez l’onglet Histogramme. Vous devrez cliquer sur le bouton Calculer l’histogramme pour générer le graphique. Un graphe décrivant la fréquence des valeurs de l’image sera alors affiché.
Vous pouvez l’exporter en tant qu’image:

Sélectionnez l’onglet Métadonnées, vous pouvez voir plus d’informations détaillées dans la boîte Propriétés.
La valeur moyenne est 332.8 et la valeur maximale vaut 1699 ! Mais ces valeurs ne s’affichent pas dans l’histogramme. Pourquoi ? C’est parce qu’il y a tellement peu de pixels qui disposent de cette valeur comparée à la valeur moyenne. C’est également pour cela que l’histogramme est aussi étendu même s’il n’y a pas de ligne rouge indiquant la fréquence des valeurs plus importantes que 250.
Par conséquent, gardez en tête qu’un histogramme vous montre la distribution des valeurs, et toutes les valeurs ne sont pas forcément visibles sur le graphe.
(Vous pouvez maintenant fermer la fenêtre Propriétés de la couche.)
7.4.7. Follow Along: Interpolation Spatiale¶
Disons que vous disposez d’un échantillon de points dont vous souhaitez extrapoler les données. Par exemple, vous avez accès au jeu de données random_samples que nous avons créé auparavant et vous voulez vous faire une idée de l’aspect du terrain.
Pour démarrer, lancez l’outil Grille (Interpolation) en cliquant dans l’entrée de menu Raster ‣ Analyse ‣ Grille (Interpolation) .
Dans le champ Fichier source, sélectionnez
random_samples.Cochez la case Champ Z, et sélectionnez le champ
srtm_41_19.Mettez l’emplacement du Fichier de sortie à
exercise_data/spatial_statistics/interpolation.tif.Cochez la case Algorithme et sélectionnez Distance inverse à une puissance.
Mettez la Puissance à
5.0et le Lissage à2.0. Laissez les autres valeurs comme elles sont.Cochez la case Charger dans la carte une fois terminé et cliquez sur OK.
Quand c’est fait, cliquez sur OK dans la boîte de dialogue qui dit kbd:Processus terminé, cliquez sur OK dans la boîte de dialogue montrant des informations de retour (si elle a apparu), et cliquez sur Fermer dans la boîte de dialogue Grille (Interpolation).
Voici une comparaison entre le jeu de données originel (gauche) et celui construit à partir de nos points (droite). Les votres peuvent sembler différents étant donné la nature aléatoire de l’emplacement des points.

Comme vous pouvez le constater, 100 points ne suffisent pas à créer un terrain détaillé. Cela donne une idée globale mais qui peut être mal interprétée. Par exemple, dans l’image ci-dessus, il n’est pas clair qu’il y ait une montagne qui traverse le terrain, de l’est vers l’ouest. Au contraire, l’image semble afficher une vallée avec des pics vers l’ouest. Une simple inspection visuelle nous permet de dire que le jeu de données n’est pas représentatif du terrain.
7.4.8.  Try Yourself¶
Try Yourself¶
Utilisez les processus montrés ci-dessus pour créer un nouveau jeu de
1000points aléatoires.Utilisez ces points pour échantilloner le MEN originel.
Utilisez l’outil Grille (Interpolation) sur ce nouveau jeu de données comme ci-dessus.
Paramétrez le nom du fichier de sortie à
interpolation_1000.tif, les paramètres Puissance and Lissage respectivement à5.0et2.0.
Les résultats (dépendamment de la position de vos points aléatoires) ressembleront plus ou moins à cela :

La frontière montre la couche roads_hull (qui représente la frontière du jeu de points aléatoires) qui explique le manque soudain de détail passé la bordure. C’est une représentation plus fidèle du terrain, dû à la plus grande densité de points d’échantillon.
Voici un exemple d’à quoi cela ressemble avec 10 000 points aléatoires :

Note
Il n’est pas recommandé de lancer ce traitement avec 10 000 points d’échantillon si vous ne travaillez pas avec une station de travail puissante car la taille du jeu de données implique beaucoup de temps de calcul.
7.4.9. Follow Along: Outils complémentaires d’analyse spatiale¶
Le logiciel SEXTANTE a été ajouté en tant que fonction de coeur de QGIS depuis la version 2.0. A lo’rigine, il était disponible en tant que projet séparé accessible depuis une extension. Vous pouvez le trouver dans le nouveau menu de QGIS Traitements où vous pourrez trouver une riche boîte à outils d’analyse spatiale de nombreuses extension, le tout à partir d’une seule interface.
Activez cet ensemble d’outils en activant l’entrée du menu Traitements ‣ Boîte à outils. La boîte à outils ressemble à ce qui suit:

Vous la trouverez probablement intégrée à la fenêtre QGIS à droite de la carte. Les outils listés ici sont des liens vers les outils réels. Quelques-uns sont les algorithmes internes de SEXTANTE et les autres sont des liens vers des outils issus d’applications externes comme GRASS, SAGA et Orfeo. Ces applications externes sont installées avec QGIS et vous pouvez les utiliser directement. Si vous avez besoin de modifier la configuration des outils Traitements, par exemple, pour mettre à jour vers une nouvelle version, vous pouvez accéder aux paramètres depuis Traitements ‣ Options et configuration.
7.4.10. Follow Along: Analyse du motif de point¶
Pour obtenir une indication simple de la distribution spatiale des points du jeu de données random_samples, nous pouvons utilise l’outil de SAGA Analyse du motif spatial de points via la Boîte à outils de traitements que vous venez d’ouvrir.
Dans la Boîte à outils Traitements, cherchez l’outil Analyse spatiale du motif de points.
Double-cliquez dessus pour ouvrir sa boîte de dialogue.
7.4.10.1. Installation de SAGA¶
Note
Si SAGA n’est pas installé sur votre système, la boîte de dialogue de l’extension vous informera que la dépendance est manquante. Si ce n’est pas le cas, vous pouvez ignorer ces étapes.
7.4.10.2. Sur Windows¶
Inclus dans votre matériel de cours, vous trouverez le programme d’installation de SAGA pour Windows.
Démarrez le programme et suivez ses instructions pour installer SAGA sur votre système Windows. Prenez note de chemin où vous l’installer !
Une fois que vous avez installé SAGA, vous devrez configurer SEXTANTE pour trouver le chemin sous lequel il a été installé.
Cliquez sur le menu Analyse ‣ Options et configuration de SAGA.
Dans la boîte de dialogue qui apparaît, étendez l’élément SAGA et cherchez Répertoire SAGA. Sa valeur est vide.
Dans cet espace, insérez le chemin d’où vous avez installé SAGA.
7.4.10.3. sur Ubuntu:¶
Cherchez la chaîne de caractères SAGA GIS dans le Software Center ou saisissez la commande
sudo apt-get install saga-gisdans votre terminal (vous aurez peut-être besoin d’ajouter le dépôt SAGA à vos sources de binaires).QGIS trouvera automatiquement SAGA, bien que vous puissiez devoir redémarrer QGIS si ça ne fonctionne pas tout de suite.
7.4.10.4. Sur Mac¶
Les utilisateurs de Homebrew peuvent installer SAGA avec cette commande:
- brew install saga-core
Si vous n’utilisez pas Homebrew, veuillez suivre les instructions ici:
http://sourceforge.net/apps/trac/saga-gis/wiki/Compiling%20SAGA%20on%20Mac%20OS%20X
7.4.10.5. Après l’installation¶
Maintenant que vous avez installé et configuré SAGA, ses fonctions deviendront accessible pour vous.
7.4.10.6. Utilisation de SAGA¶
Ouvrez la boîte de dialogue SAGA.
SAGA produit trois sorties, et demandera donc trois chemins de sortie.
Sauvegardez ces trois sorties sous
exercise_data/spatial_statistics/, en utilisant tous les noms de fichiers que vous trouvez appropriés.

Le rendu ressemblera à cela (la symbologie a été changée pour cet exemple) :

Le point rouge indique la moyenne, le cercle large indique la distance standard qui donne une indication sur la distribution des points par rapport à la moyenne. Le rectangle indique l’emprise la plus petite contenant tous les points.
7.4.11. Follow Along: Analyse de la distance minimale¶
Souvent, la sortie d’un algorithme ne sera pas un shapefile, mais plutôt une table résumant les propriétés statistiques d’un jeu de données. L’un d’eux est l’outil Analyse de la distance minimale.
Trouvez cet outil dans la Boîte à outils Traitements sous Analyse de la distance minimale.
Il n’y a pas d’autres entrées que le jeu de données de points à analyser.
Choisissez le jeu de données random_points.
Cliquez sur OK. À la fin, une table DBF apparaîtra dans la Légende de la carte.
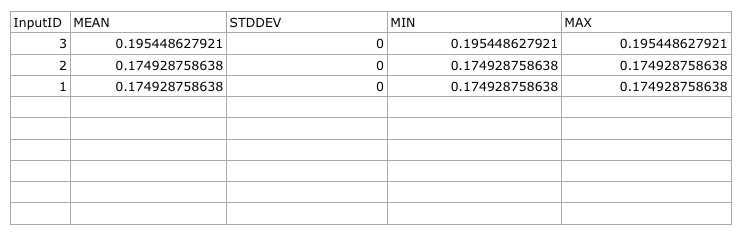
Sélectionnez-la puis ouvrez sa table attributaire. Bien que les chiffres peuvent varier, vos résultats seront dans ce format :

7.4.12. In Conclusion¶
QGIS permet de nombreuses possibilités pour l’analyse des propriétés statistiques spatiales des jeu de données.
7.4.13. What’s Next?¶
Maintenant que nous avons couvert l’analyse vectorielle, pourquoi ne pas voir ce qu’il peut être fait avec des rasters ? C’est ce que nous ferons dans le prochain module !