17.14. Premier exemple d’analyse¶
Note
Dans cette leçon, nous effectuerons une véritable analyse en utilisant uniquement la boîte à outils, afin que vous puissiez vous familiariser avec les éléments du module de traitements.
Maintenant que tout est configuré et que nous pouvons utiliser des algorithmes externes, nous avons un outil très puissant pour effectuer une analyse spatiale. Il est temps de réaliser un exercice plus important avec des données du monde réel.
Nous utiliserons le fameux set de données que John Snow utilisa en 1854 dans son œuvre révolutionnaire (http://en.wikipedia.org/wiki/John_Snow_%28physician%29), et nous obtiendrons des résultats intéressants. L’analyse de ce set de données est presque triviale et les techniques sophistiquées de SIG ne sont pas nécessaires pour obtenir de bons résultats et conclusions, mais c’est une bonne façon de montrer comment ces problèmes spatiaux peuvent être analysés et résolus par l’utilisation d’outils de traitement différents.
Le jeu de données contient des fichiers Shape qui référencent les décès dus au choléra, les emplacements des pompes à eau ainsi qu’une carte raster issue d’OSM au format TIFF. Ouvrez le projet QGIS correspondant à cette leçon.

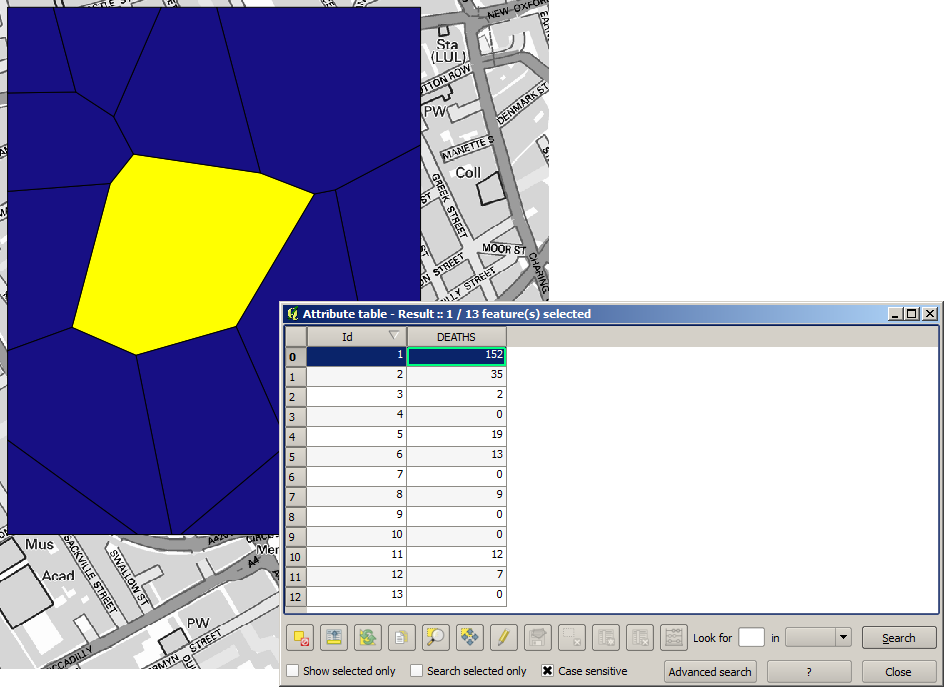
La première chose à faire est de calculer le diagramme de Voronoï (aussi connu sous le nom des polygones de Thyessen) de la couche des pompes, pour obtenir la zone d’influence pour chaque pompe. L’algorithme du Diagramme de Voronoï peut être utilisé pour cela.

C’est assez facile, mais cela nous donne déjà des informations intéressantes.

Il est clair que la plupart des cas soient dans un des polygones.
Pour obtenir un résultat plus quantitatif, nous pouvons compter le nombre de décès dans chaque polygones. Comme chaque point représente un bâtiment où il y a eu un ou des décès, et que le nombre de décès est stocké dans un attribut, nous ne pouvons pas simplement compter les points. Nous avons besoin d’un nombre pondéré, donc nous utiliserons l’outil Compter les points dans les polygones (pondérés).

Le nouveau champ sera appelé DEATHS, et nous utiliserons le champ COUNT comme champ de pondération. La table de résultats reflète clairement que le nombre de décès dans le polygone correspondant à la première pompe est beaucoup plus grand que celui des autres.
Une autre bonne façon de visualiser la dépendance de chaque point dans la couche Cholera_deaths avec un point dans la couche Pumps est de dessiner une ligne vers le plus proche. Cela peut être fait avec l’outil Distance au nœud le plus proche, et en utilisant la configuration montrée ci-après.

Le résultat ressemble à cela :
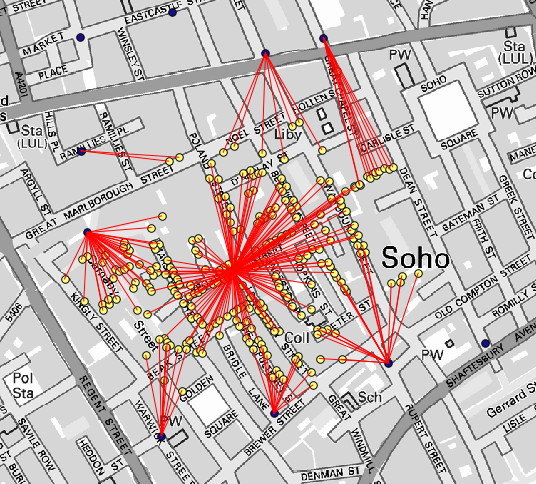
Bien que le nombre de lignes soit plus grand dans le cas de la pompe centrale, n’oubliez pas que cela ne représente par le nombre de décès, mais le nombre de lieux où des cas de choléra ont été détecté. C’est un paramètre représentatif, mais il ne considère pas que certains emplacements puissent représenter plus de cas qu’un autre.
Une couche de densité nous donnera aussi une vision très claire de ce qu’il se passe. Nous pouvons la créer avec l’algorithme Densité par noyau. En utilisant la couche Cholera_deaths et son champ COUNT comme champ de pondération, avec un rayon de 100 ainsi que l’emprise et la taille des cellule de la couche raster des rues, nous obtenons quelque chose comme ça.

Souvenez-vous que pour obtenir l’emprise de sortie, vous ne devez pas la taper. Cliquez sur le bouton sur le côté droit et sélectionnez Utiliser l’emprise de la couche/du canevas.

Sélectionnez la couche raster des routes et son étendue sera automatiquement ajoutée au champ de texte. Vous devez faire de même avec la taille de cellule, en sélectionnant la taille de cellule de cette couche.
En combinant la couche des pompes, nous voyons qu’il y a une pompe qui se trouve clairement dans le point chaud où la densité maximale de cas de décès a été trouvée.