17.22. 심화 보간법¶
주석
이 강의에서는 보간법 알고리듬을 사용하는 또다른 실질적인 사례를 배울 것입니다.
보간법은 일반적인 기법으로, QGIS 공간처리 프레임워크를 사용해 적용할 수 있는 몇 가지 기술을 시연하는 데 쓰일 수 있습니다. 이 강의에서는 앞에서 이미 언급했던 몇몇 보간법 알고리듬을 사용하지만, 다르게 접근해볼 것입니다.
이 강의를 위한 데이터는 표고 데이터를 담고 있는 포인트 레이어 하나입니다. 이전 강의에서와 거의 동일한 방법으로 보간할 것이지만, 이번에는 보간 처리의 질을 평가하는데 사용하기 위해 원래 데이터의 일부를 보전할 것입니다.
먼저, 포인트 레이어를 래스터화하고 결과물의 비 데이터 셀을 채워야 합니다. 다만 레이어가 담고 있는 포인트의 일부만을 사용할 것입니다. 이후에 확인하기 위해 포인트 가운데 10%를 보전할 것이므로, 보간하기 위한 90%의 포인트를 준비해야 합니다. 이를 위해 Split shapes layer randomly 알고리듬을 쓸 수 있습니다. 이전 강의에서 벌써 사용해본 알고리듬이지만, 새로운 중간 단계 레이어를 생성할 필요가 없는 더 나은 방법이 있습니다. 중간 단계 대신, 보간하고자 하는 (90% 부분) 포인트를 선택한 다음 알고리듬을 실행하면 됩니다. 이미 배웠듯이, 래스터화 알고리듬은 선택한 포인트만 사용하고 나머지는 무시합니다. Random selection 알고리듬을 통해 선택 집합을 만들 수 있습니다. 다음 파라미터 값을 써서 실행하십시오.
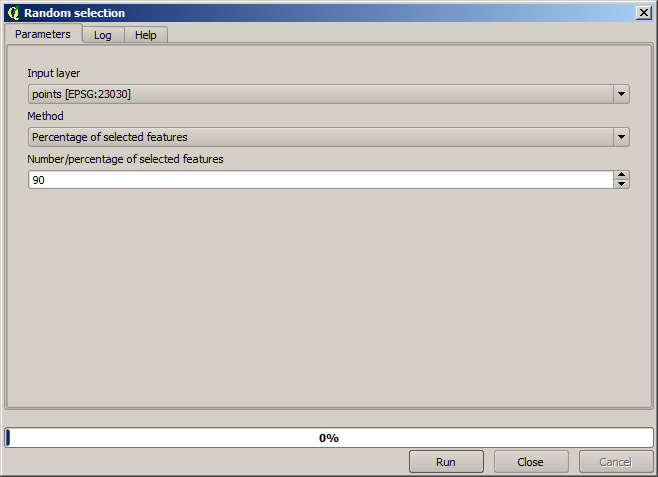
래스터화할 레이어에 있는 포인트 가운데 90%를 선택할 것입니다.

랜덤하게 선택하기 때문에, 앞의 그림에 보이는 선택 집합과 사용자의 선택 집합이 서로 다를 수도 있습니다.
Now run the Shapes to grid algorithm to get the first raster layer, and then run the Close gaps algorithm to fill the no–data cells [Cell resolution: 100 m].

보간 결과의 질을 확인하기 위해, 이제 선택하지 않은 포인트를 사용할 수 있습니다. 이 시점에서 (포인트 레이어의 값인) 실제 표고와 (보간 처리된 래스터 레이어의 값인) 보간된 표고를 알고 있습니다. 이 두 값들의 차이를 계산해서 비교해볼 수 있습니다.
선택하지 않은 포인트를 사용할 것이므로, 먼저 선택을 반전시킵시다.

The points contain the original values, but not the interpolated ones. To add them in a new field, we can use the Add grid values to points algorithm
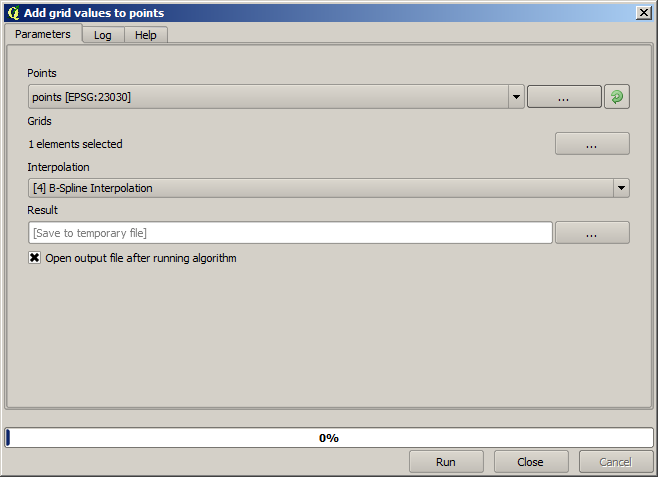
선택해야 할 래스터 레이어는 (해당 알고리듬이 복수의 레이어를 지원하지만, 이 경우 하나만 필요합니다) 보간법 알고리듬의 결과물입니다. 해당 레이어의 명칭을 interpolate 로 변경하고, 이 레이어명을 추가할 필드의 명칭으로 사용할 것입니다.
이제 보간 처리에 쓰이지 않았던 포인트가 두 가지 값을 담고 있는 벡터 레이어를 얻었습니다.
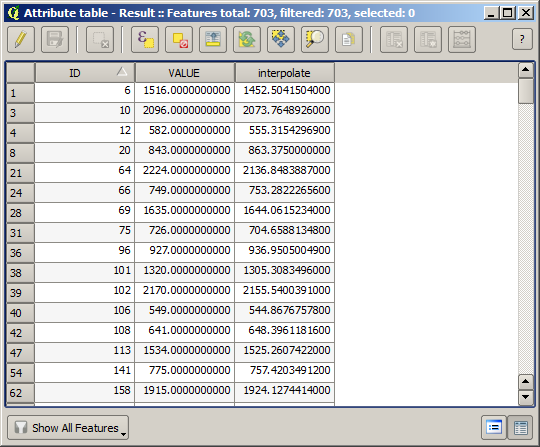
다음 작업에 필드 계산기를 사용할 것입니다. Field calculator 알고리듬을 열고 다음 파라미터 값을 써서 실행하십시오.

래스터 레이어에서 가져온 값을 담은 필드명을 다른 명칭으로 정했다면, 앞의 그림에 나온 공식을 그에 맞춰 수정해야 합니다. 이 알고리듬을 실행하면, 보간 처리에 쓰이지 않았던 포인트가 두 가지 표고 값의 차를 담고 있는 새 레이어를 얻게 됩니다.
이 차이 값에 따라 레이어를 렌더링하면, 불일치가 가장 크게 발생하는 곳이 어디인지 감을 잡을 수 있습니다.
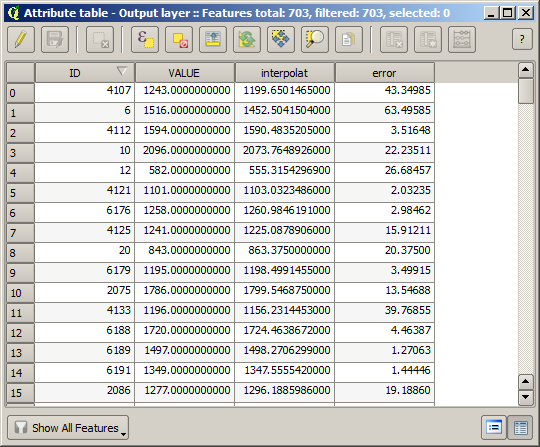
해당 레이어를 보간하면, 보간된 지역의 모든 포인트에서 측정된 오류를 나타내는 래스터 레이어를 얻게 됩니다.
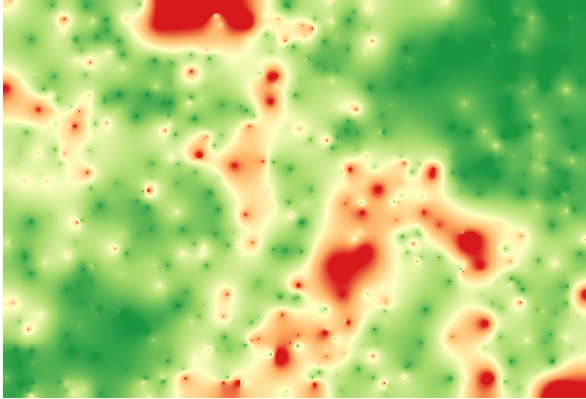
또한 동일한 정보(원래 포인트 값과 보간된 포인트 값의 차이)를 GRASS ‣ v.sample 메뉴를 통해 얻을 수 있습니다.
이 강의의 시작 부분에서 설명한 대로, Random selection 알고리듬 실행 시 랜덤 이라는 요소가 관여하므로 사용자의 결과는 앞의 그림과 다를 수도 있습니다.